Looker is currently in beta. The info in this guide is subject to change.
This integration is powered by Singer's Looker tap. For support, visit the GitHub repo or join the Singer Slack.
Looker integration summary
Stitch’s Looker integration replicates data using the Looker v4 API. Refer to the Schema section for a list of objects available for replication.
Looker feature snapshot
A high-level look at Stitch's Looker (v1) integration, including release status, useful links, and the features supported in Stitch.
| STITCH | |||
| Release status |
Beta |
Supported by | |
| Stitch plan |
Standard |
API availability |
Available |
| Singer GitHub repository | |||
| REPLICATION SETTINGS | |||
| Anchor Scheduling |
Supported |
Advanced Scheduling |
Supported |
| Table-level reset |
Unsupported |
Configurable Replication Methods |
Unsupported |
| DATA SELECTION | |||
| Table selection |
Supported |
Column selection |
Supported |
| Select all |
Supported |
||
| TRANSPARENCY | |||
| Extraction Logs |
Supported |
Loading Reports |
Supported |
Connecting Looker
Looker setup requirements
To set up Looker in Stitch, you need:
-
Looker Admin privileges. Admin privileges in Looker are required to generate credentials for Stitch.
Step 1: Generate Looker API credentials for Stitch
- Sign into your Looker account.
- Navigate to the Edit Users page.
- Click the Edit Keys button. This will take you to the Edit User API3 Keys page.
- Click the New API3 key button to generate a new key.
- Copy your Client ID and Client Secret. Keep it readily available for the next step.
Step 2: Add Looker as a Stitch data source
- Sign into your Stitch account.
-
On the Stitch Dashboard page, click the Add Integration button.
-
Click the Looker icon.
-
Enter a name for the integration. This is the name that will display on the Stitch Dashboard for the integration; it’ll also be used to create the schema in your destination.
For example, the name “Stitch Looker” would create a schema called
stitch_lookerin the destination. Note: Schema names cannot be changed after you save the integration. - In the API Port field, enter your API Port number. Note: This value is usually
19999unless you host Looker internally. If hosting internally, use your internal API Port value. - In the Client ID field, paste the Client ID that you copied in Step 1.
- In the Client Secret field, paste the Client Secret that you copied in Step 1.
- In the Domain field, enter your Looker account domain. It’s typically
looker.com, unless you use a white-labeled URL. - In the Subdomain field, enter your Looker account subdomain. Your subdomain is the leading part of your Looker URL. For example: If the URL is
https://stitch.looker.com, the value for this field would bestitch.
Step 3: Define the historical replication start date
The Sync Historical Data setting defines the starting date for your Looker integration. This means that data equal to or newer than this date will be replicated to your data warehouse.
Change this setting if you want to replicate data beyond Looker’s default setting of 1 year. For a detailed look at historical replication jobs, check out the Syncing Historical SaaS Data guide.
Step 4: Create a replication schedule
In the Replication Frequency section, you’ll create the integration’s replication schedule. An integration’s replication schedule determines how often Stitch runs a replication job, and the time that job begins.
Looker integrations support the following replication scheduling methods:
-
Advanced Scheduling using Cron (Advanced or Premium plans only)
To keep your row usage low, consider setting the integration to replicate less frequently. See the Understanding and Reducing Your Row Usage guide for tips on reducing your usage.
Step 5: Set objects to replicate
The last step is to select the tables and columns you want to replicate. Learn about the available tables for this integration.
Note: If a replication job is currently in progress, new selections won’t be used until the next job starts.
For Looker integrations, you can select:
-
Individual tables and columns
-
All tables and columns
Click the tabs to view instructions for each selection method.
- In the integration’s Tables to Replicate tab, locate a table you want to replicate.
-
To track a table, click the checkbox next to the table’s name. A blue checkmark means the table is set to replicate.
-
To track a column, click the checkbox next to the column’s name. A blue checkmark means the column is set to replicate.
- Repeat this process for all the tables and columns you want to replicate.
- When finished, click the Finalize Your Selections button at the bottom of the screen to save your selections.
- Click into the integration from the Stitch Dashboard page.
-
Click the Tables to Replicate tab.
- In the list of tables, click the box next to the Table Names column.
-
In the menu that displays, click Track all Tables and Fields:
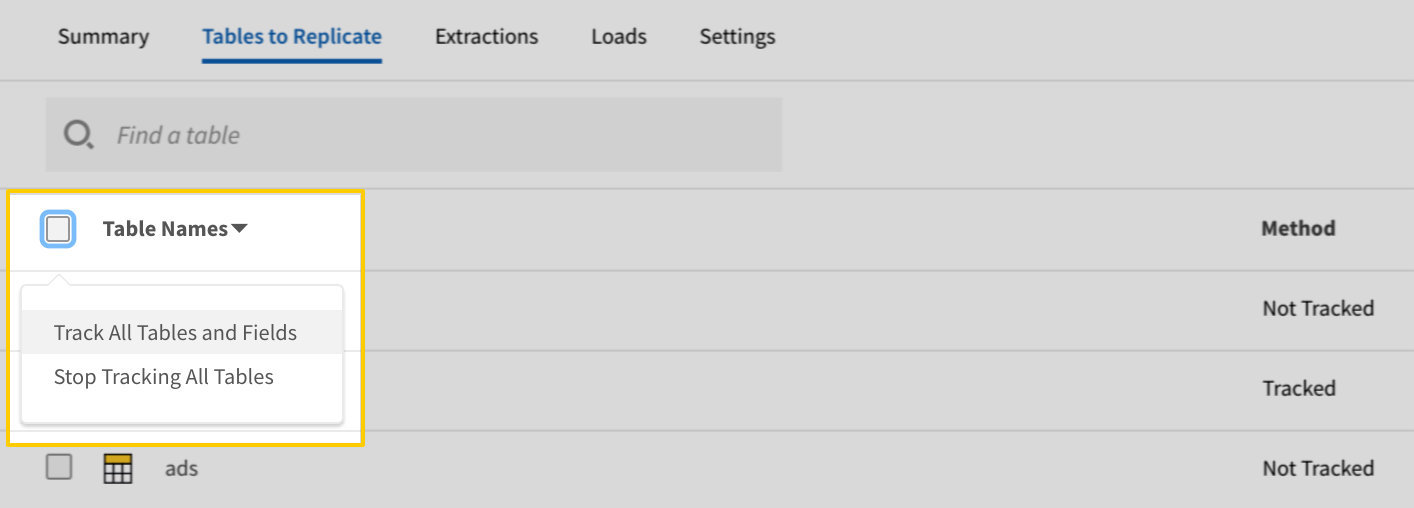
- Click the Finalize Your Selections button at the bottom of the page to save your data selections.
Initial and historical replication jobs
After you finish setting up Looker, its Sync Status may show as Pending on either the Stitch Dashboard or in the Integration Details page.
For a new integration, a Pending status indicates that Stitch is in the process of scheduling the initial replication job for the integration. This may take some time to complete.
Initial replication jobs with Anchor Scheduling
If using Anchor Scheduling, an initial replication job may not kick off immediately. This depends on the selected Replication Frequency and Anchor Time. Refer to the Anchor Scheduling documentation for more information.
Free historical data loads
The first seven days of replication, beginning when data is first replicated, are free. Rows replicated from the new integration during this time won’t count towards your quota. Stitch offers this as a way of testing new integrations, measuring usage, and ensuring historical data volumes don’t quickly consume your quota.
Looker table reference
Schemas and versioning
Schemas and naming conventions can change from version to version, so we recommend verifying your integration’s version before continuing.
The schema and info displayed below is for version 1 of this integration.
This is the latest version of the Looker integration.
Table and column names in your destination
Depending on your destination, table and column names may not appear as they are outlined below.
For example: Object names are lowercased in Redshift (CusTomERs > customers), while case is maintained in PostgreSQL destinations (CusTomERs > CusTomERs). Refer to the Loading Guide for your destination for more info.
color_collections
The color_collections table contains information about color collections in your Looker account.
|
Full Table |
|
|
Primary Key |
id |
| Useful links |
| Join color_collections with | on |
|---|---|
| themes |
color_collections.id = themes.settings.color_collection_id |
|
categoricalPalettes ARRAY
|
||||||
|
divergingPalettes ARRAY
|
||||||
|
id
STRING |
||||||
|
label STRING |
||||||
|
sequentialPalettes ARRAY
|
connections
The connections table contains information about connections in your Looker account.
|
Full Table |
|
|
Primary Key |
name |
| Useful links |
| Join connections with | on |
|---|---|
| content_favorites |
connections.user_id = content_favorites.dashboard.folder.creator_id connections.user_id = content_favorites.dashboard.space.creator_id connections.user_id = content_favorites.user_id |
| content_views |
connections.user_id = content_views.user_id |
| dashboard_elements |
connections.user_id = dashboard_elements.look.deleter_id connections.user_id = dashboard_elements.look.folder.creator_id connections.user_id = dashboard_elements.look.last_updater_id connections.user_id = dashboard_elements.look.space.creator_id connections.user_id = dashboard_elements.look.user.id connections.user_id = dashboard_elements.look.user_id |
| dashboards |
connections.user_id = dashboards.space.creator_id connections.user_id = dashboards.user_id |
| folders |
connections.user_id = folders.creator_id connections.user_id = folders.dashboards.user_id connections.user_id = folders.dashboards.folder.creator_id connections.user_id = folders.dashboards.space.creator_id connections.user_id = folders.looks.deleter_id connections.user_id = folders.looks.last_updater_id connections.user_id = folders.looks.user.id |
| lookml_dashboards |
connections.user_id = lookml_dashboards.folder.creator_id connections.user_id = lookml_dashboards.space.creator_id connections.user_id = lookml_dashboards.user_id |
| looks |
connections.user_id = looks.deleter_id connections.user_id = looks.folder.creator_id connections.user_id = looks.user.id connections.user_id = looks.user_id |
| scheduled_plans |
connections.user_id = scheduled_plans.user.id connections.user_id = scheduled_plans.user_id |
| user_login_lockouts |
connections.user_id = user_login_lockouts.user_id |
| users |
connections.user_id = users.id |
|
after_connect_statements STRING |
||||||||||||
|
certificate STRING |
||||||||||||
|
created_at STRING |
||||||||||||
|
database STRING |
||||||||||||
|
db_timezone STRING |
||||||||||||
|
dialect OBJECT
|
||||||||||||
|
dialect_name STRING |
||||||||||||
|
example BOOLEAN |
||||||||||||
|
file_type STRING |
||||||||||||
|
host STRING |
||||||||||||
|
jdbc_additional_params STRING |
||||||||||||
|
last_reap_at INTEGER |
||||||||||||
|
last_regen_at INTEGER |
||||||||||||
|
maintenance_cron STRING |
||||||||||||
|
max_billing_gigabytes NUMBER |
||||||||||||
|
max_connections INTEGER |
||||||||||||
|
name
STRING |
||||||||||||
|
password STRING |
||||||||||||
|
pdt_context_override OBJECT
|
||||||||||||
|
pool_timeout INTEGER |
||||||||||||
|
port STRING |
||||||||||||
|
query_timezone STRING |
||||||||||||
|
schema STRING |
||||||||||||
|
snippets ARRAY
|
||||||||||||
|
sql_runner_precache_tables BOOLEAN |
||||||||||||
|
ssl BOOLEAN |
||||||||||||
|
tmp_db_name STRING |
||||||||||||
|
user_attribute_fields ARRAY |
||||||||||||
|
user_db_credentials BOOLEAN |
||||||||||||
|
user_id STRING |
||||||||||||
|
username STRING |
||||||||||||
|
uses_oauth BOOLEAN |
||||||||||||
|
verify_ssl BOOLEAN |
content_favorites
The content_favorites table contains info about users’ favorite content in your Looker instance.
|
Full Table |
|
|
Primary Key |
id |
| Useful links |
| Join content_favorites with | on |
|---|---|
| dashboard_elements |
content_favorites.id = dashboard_elements.look.content_favorite_id content_favorites.dashboard.content_favorite_id = dashboard_elements.look.content_favorite_id content_favorites.content_metadata_id = dashboard_elements.look.content_metadata_id content_favorites.dashboard.content_metadata_id = dashboard_elements.look.content_metadata_id content_favorites.dashboard.folder.content_metadata_id = dashboard_elements.look.content_metadata_id content_favorites.dashboard.space.content_metadata_id = dashboard_elements.look.content_metadata_id content_favorites.look.content_metadata_id = dashboard_elements.look.content_metadata_id content_favorites.content_metadata_id = dashboard_elements.look.folder.content_metadata_id content_favorites.dashboard.content_metadata_id = dashboard_elements.look.folder.content_metadata_id content_favorites.dashboard.folder.content_metadata_id = dashboard_elements.look.folder.content_metadata_id content_favorites.dashboard.space.content_metadata_id = dashboard_elements.look.folder.content_metadata_id content_favorites.look.content_metadata_id = dashboard_elements.look.folder.content_metadata_id content_favorites.content_metadata_id = dashboard_elements.look.space.content_metadata_id content_favorites.dashboard.content_metadata_id = dashboard_elements.look.space.content_metadata_id content_favorites.dashboard.folder.content_metadata_id = dashboard_elements.look.space.content_metadata_id content_favorites.dashboard.space.content_metadata_id = dashboard_elements.look.space.content_metadata_id content_favorites.look.content_metadata_id = dashboard_elements.look.space.content_metadata_id content_favorites.dashboard.id = dashboard_elements.dashboard_id content_favorites.dashboard_id = dashboard_elements.dashboard_id content_favorites.dashboard.folder.id = dashboard_elements.look.folder.id content_favorites.dashboard.folder.parent_id = dashboard_elements.look.folder.id content_favorites.dashboard.folder.id = dashboard_elements.look.folder.parent_id content_favorites.dashboard.folder.parent_id = dashboard_elements.look.folder.parent_id content_favorites.dashboard.folder.id = dashboard_elements.look.folder_id content_favorites.dashboard.folder.parent_id = dashboard_elements.look.folder_id content_favorites.look_id = dashboard_elements.look.id content_favorites.look.id = dashboard_elements.look.id content_favorites.look_id = dashboard_elements.look_id content_favorites.look.id = dashboard_elements.look_id content_favorites.dashboard.model.id = dashboard_elements.look.model.id content_favorites.dashboard.space.id = dashboard_elements.look.space.id content_favorites.dashboard.space.parent_id = dashboard_elements.look.space.id content_favorites.dashboard.space.id = dashboard_elements.look.space.parent_id content_favorites.dashboard.space.parent_id = dashboard_elements.look.space.parent_id content_favorites.dashboard.folder.creator_id = dashboard_elements.look.deleter_id content_favorites.dashboard.space.creator_id = dashboard_elements.look.deleter_id content_favorites.user_id = dashboard_elements.look.deleter_id content_favorites.dashboard.folder.creator_id = dashboard_elements.look.folder.creator_id content_favorites.dashboard.space.creator_id = dashboard_elements.look.folder.creator_id content_favorites.user_id = dashboard_elements.look.folder.creator_id content_favorites.dashboard.folder.creator_id = dashboard_elements.look.last_updater_id content_favorites.dashboard.space.creator_id = dashboard_elements.look.last_updater_id content_favorites.user_id = dashboard_elements.look.last_updater_id content_favorites.dashboard.folder.creator_id = dashboard_elements.look.space.creator_id content_favorites.dashboard.space.creator_id = dashboard_elements.look.space.creator_id content_favorites.user_id = dashboard_elements.look.space.creator_id content_favorites.dashboard.folder.creator_id = dashboard_elements.look.user.id content_favorites.dashboard.space.creator_id = dashboard_elements.look.user.id content_favorites.user_id = dashboard_elements.look.user.id content_favorites.dashboard.folder.creator_id = dashboard_elements.look.user_id content_favorites.dashboard.space.creator_id = dashboard_elements.look.user_id content_favorites.user_id = dashboard_elements.look.user_id |
| dashboards |
content_favorites.id = dashboards.content_favorite_id content_favorites.dashboard.content_favorite_id = dashboards.content_favorite_id content_favorites.content_metadata_id = dashboards.content_metadata_id content_favorites.dashboard.content_metadata_id = dashboards.content_metadata_id content_favorites.dashboard.folder.content_metadata_id = dashboards.content_metadata_id content_favorites.dashboard.space.content_metadata_id = dashboards.content_metadata_id content_favorites.look.content_metadata_id = dashboards.content_metadata_id content_favorites.content_metadata_id = dashboards.folder.content_metadata_id content_favorites.dashboard.content_metadata_id = dashboards.folder.content_metadata_id content_favorites.dashboard.folder.content_metadata_id = dashboards.folder.content_metadata_id content_favorites.dashboard.space.content_metadata_id = dashboards.folder.content_metadata_id content_favorites.look.content_metadata_id = dashboards.folder.content_metadata_id content_favorites.content_metadata_id = dashboards.space.content_metadata_id content_favorites.dashboard.content_metadata_id = dashboards.space.content_metadata_id content_favorites.dashboard.folder.content_metadata_id = dashboards.space.content_metadata_id content_favorites.dashboard.space.content_metadata_id = dashboards.space.content_metadata_id content_favorites.look.content_metadata_id = dashboards.space.content_metadata_id content_favorites.dashboard.id = dashboards.id content_favorites.dashboard_id = dashboards.id content_favorites.dashboard.folder.id = dashboards.folder.id content_favorites.dashboard.folder.parent_id = dashboards.folder.id content_favorites.dashboard.folder.id = dashboards.folder.parent_id content_favorites.dashboard.folder.parent_id = dashboards.folder.parent_id content_favorites.dashboard.model.id = dashboards.model.id content_favorites.dashboard.space.id = dashboards.space.id content_favorites.dashboard.space.parent_id = dashboards.space.id content_favorites.dashboard.space.id = dashboards.space.parent_id content_favorites.dashboard.space.parent_id = dashboards.space.parent_id content_favorites.dashboard.folder.creator_id = dashboards.space.creator_id content_favorites.dashboard.space.creator_id = dashboards.space.creator_id content_favorites.user_id = dashboards.space.creator_id content_favorites.dashboard.folder.creator_id = dashboards.user_id content_favorites.dashboard.space.creator_id = dashboards.user_id content_favorites.user_id = dashboards.user_id |
| folders |
content_favorites.id = folders.dashboards.content_favorite_id content_favorites.dashboard.content_favorite_id = folders.dashboards.content_favorite_id content_favorites.id = folders.looks.content_favorite_id content_favorites.dashboard.content_favorite_id = folders.looks.content_favorite_id content_favorites.content_metadata_id = folders.dashboards.folder.content_metadata_id content_favorites.dashboard.content_metadata_id = folders.dashboards.folder.content_metadata_id content_favorites.dashboard.folder.content_metadata_id = folders.dashboards.folder.content_metadata_id content_favorites.dashboard.space.content_metadata_id = folders.dashboards.folder.content_metadata_id content_favorites.look.content_metadata_id = folders.dashboards.folder.content_metadata_id content_favorites.content_metadata_id = folders.dashboards.space.content_metadata_id content_favorites.dashboard.content_metadata_id = folders.dashboards.space.content_metadata_id content_favorites.dashboard.folder.content_metadata_id = folders.dashboards.space.content_metadata_id content_favorites.dashboard.space.content_metadata_id = folders.dashboards.space.content_metadata_id content_favorites.look.content_metadata_id = folders.dashboards.space.content_metadata_id content_favorites.content_metadata_id = folders.looks.content_metadata_id content_favorites.dashboard.content_metadata_id = folders.looks.content_metadata_id content_favorites.dashboard.folder.content_metadata_id = folders.looks.content_metadata_id content_favorites.dashboard.space.content_metadata_id = folders.looks.content_metadata_id content_favorites.look.content_metadata_id = folders.looks.content_metadata_id content_favorites.content_metadata_id = folders.looks.folder.content_metadata_id content_favorites.dashboard.content_metadata_id = folders.looks.folder.content_metadata_id content_favorites.dashboard.folder.content_metadata_id = folders.looks.folder.content_metadata_id content_favorites.dashboard.space.content_metadata_id = folders.looks.folder.content_metadata_id content_favorites.look.content_metadata_id = folders.looks.folder.content_metadata_id content_favorites.dashboard.id = folders.dashboards.id content_favorites.dashboard_id = folders.dashboards.id content_favorites.dashboard.folder.id = folders.id content_favorites.dashboard.folder.parent_id = folders.id content_favorites.dashboard.folder.id = folders.dashboards.folder.id content_favorites.dashboard.folder.parent_id = folders.dashboards.folder.id content_favorites.dashboard.folder.id = folders.dashboards.folder.parent_id content_favorites.dashboard.folder.parent_id = folders.dashboards.folder.parent_id content_favorites.dashboard.folder.id = folders.looks.folder.id content_favorites.dashboard.folder.parent_id = folders.looks.folder.id content_favorites.dashboard.folder.id = folders.looks.folder.parent_id content_favorites.dashboard.folder.parent_id = folders.looks.folder.parent_id content_favorites.dashboard.folder.id = folders.parent_id content_favorites.dashboard.folder.parent_id = folders.parent_id content_favorites.look_id = folders.looks.id content_favorites.look.id = folders.looks.id content_favorites.dashboard.model.id = folders.dashboards.model.id content_favorites.dashboard.model.id = folders.looks.model.id content_favorites.dashboard.space.id = folders.dashboards.space.id content_favorites.dashboard.space.parent_id = folders.dashboards.space.id content_favorites.dashboard.space.id = folders.dashboards.space.parent_id content_favorites.dashboard.space.parent_id = folders.dashboards.space.parent_id content_favorites.dashboard.space.id = folders.looks.space.id content_favorites.dashboard.space.parent_id = folders.looks.space.id content_favorites.dashboard.space.id = folders.looks.space.parent_id content_favorites.dashboard.space.parent_id = folders.looks.space.parent_id content_favorites.dashboard.space.id = folders.looks.space_id content_favorites.dashboard.space.parent_id = folders.looks.space_id content_favorites.dashboard.folder.creator_id = folders.creator_id content_favorites.dashboard.space.creator_id = folders.creator_id content_favorites.user_id = folders.creator_id content_favorites.dashboard.folder.creator_id = folders.dashboards.user_id content_favorites.dashboard.space.creator_id = folders.dashboards.user_id content_favorites.user_id = folders.dashboards.user_id content_favorites.dashboard.folder.creator_id = folders.dashboards.folder.creator_id content_favorites.dashboard.space.creator_id = folders.dashboards.folder.creator_id content_favorites.user_id = folders.dashboards.folder.creator_id content_favorites.dashboard.folder.creator_id = folders.dashboards.space.creator_id content_favorites.dashboard.space.creator_id = folders.dashboards.space.creator_id content_favorites.user_id = folders.dashboards.space.creator_id content_favorites.dashboard.folder.creator_id = folders.looks.deleter_id content_favorites.dashboard.space.creator_id = folders.looks.deleter_id content_favorites.user_id = folders.looks.deleter_id content_favorites.dashboard.folder.creator_id = folders.looks.last_updater_id content_favorites.dashboard.space.creator_id = folders.looks.last_updater_id content_favorites.user_id = folders.looks.last_updater_id content_favorites.dashboard.folder.creator_id = folders.looks.user.id content_favorites.dashboard.space.creator_id = folders.looks.user.id content_favorites.user_id = folders.looks.user.id |
| lookml_dashboards |
content_favorites.id = lookml_dashboards.content_favorite_id content_favorites.dashboard.content_favorite_id = lookml_dashboards.content_favorite_id content_favorites.content_metadata_id = lookml_dashboards.content_metadata_id content_favorites.dashboard.content_metadata_id = lookml_dashboards.content_metadata_id content_favorites.dashboard.folder.content_metadata_id = lookml_dashboards.content_metadata_id content_favorites.dashboard.space.content_metadata_id = lookml_dashboards.content_metadata_id content_favorites.look.content_metadata_id = lookml_dashboards.content_metadata_id content_favorites.content_metadata_id = lookml_dashboards.folder.content_metadata_id content_favorites.dashboard.content_metadata_id = lookml_dashboards.folder.content_metadata_id content_favorites.dashboard.folder.content_metadata_id = lookml_dashboards.folder.content_metadata_id content_favorites.dashboard.space.content_metadata_id = lookml_dashboards.folder.content_metadata_id content_favorites.look.content_metadata_id = lookml_dashboards.folder.content_metadata_id content_favorites.content_metadata_id = lookml_dashboards.space.content_metadata_id content_favorites.dashboard.content_metadata_id = lookml_dashboards.space.content_metadata_id content_favorites.dashboard.folder.content_metadata_id = lookml_dashboards.space.content_metadata_id content_favorites.dashboard.space.content_metadata_id = lookml_dashboards.space.content_metadata_id content_favorites.look.content_metadata_id = lookml_dashboards.space.content_metadata_id content_favorites.dashboard.folder.id = lookml_dashboards.folder.id content_favorites.dashboard.folder.parent_id = lookml_dashboards.folder.id content_favorites.dashboard.folder.id = lookml_dashboards.folder.parent_id content_favorites.dashboard.folder.parent_id = lookml_dashboards.folder.parent_id content_favorites.dashboard.model.id = lookml_dashboards.model.id content_favorites.dashboard.space.id = lookml_dashboards.space.id content_favorites.dashboard.space.parent_id = lookml_dashboards.space.id content_favorites.dashboard.space.id = lookml_dashboards.space.parent_id content_favorites.dashboard.space.parent_id = lookml_dashboards.space.parent_id content_favorites.dashboard.folder.creator_id = lookml_dashboards.folder.creator_id content_favorites.dashboard.space.creator_id = lookml_dashboards.folder.creator_id content_favorites.user_id = lookml_dashboards.folder.creator_id content_favorites.dashboard.folder.creator_id = lookml_dashboards.space.creator_id content_favorites.dashboard.space.creator_id = lookml_dashboards.space.creator_id content_favorites.user_id = lookml_dashboards.space.creator_id content_favorites.dashboard.folder.creator_id = lookml_dashboards.user_id content_favorites.dashboard.space.creator_id = lookml_dashboards.user_id content_favorites.user_id = lookml_dashboards.user_id |
| looks |
content_favorites.id = looks.content_favorite_id content_favorites.dashboard.content_favorite_id = looks.content_favorite_id content_favorites.content_metadata_id = looks.content_metadata_id content_favorites.dashboard.content_metadata_id = looks.content_metadata_id content_favorites.dashboard.folder.content_metadata_id = looks.content_metadata_id content_favorites.dashboard.space.content_metadata_id = looks.content_metadata_id content_favorites.look.content_metadata_id = looks.content_metadata_id content_favorites.dashboard.folder.id = looks.folder.id content_favorites.dashboard.folder.parent_id = looks.folder.id content_favorites.dashboard.folder.id = looks.folder_id content_favorites.dashboard.folder.parent_id = looks.folder_id content_favorites.dashboard.folder.id = looks.folder.parent_id content_favorites.dashboard.folder.parent_id = looks.folder.parent_id content_favorites.look_id = looks.id content_favorites.look.id = looks.id content_favorites.dashboard.model.id = looks.model.id content_favorites.dashboard.space.id = looks.space.id content_favorites.dashboard.space.parent_id = looks.space.id content_favorites.dashboard.space.id = looks.space.parent_id content_favorites.dashboard.space.parent_id = looks.space.parent_id content_favorites.dashboard.space.id = looks.space_id content_favorites.dashboard.space.parent_id = looks.space_id content_favorites.dashboard.folder.creator_id = looks.deleter_id content_favorites.dashboard.space.creator_id = looks.deleter_id content_favorites.user_id = looks.deleter_id content_favorites.dashboard.folder.creator_id = looks.folder.creator_id content_favorites.dashboard.space.creator_id = looks.folder.creator_id content_favorites.user_id = looks.folder.creator_id content_favorites.dashboard.folder.creator_id = looks.user.id content_favorites.dashboard.space.creator_id = looks.user.id content_favorites.user_id = looks.user.id content_favorites.dashboard.folder.creator_id = looks.user_id content_favorites.dashboard.space.creator_id = looks.user_id content_favorites.user_id = looks.user_id |
| content_metadata |
content_favorites.content_metadata_id = content_metadata.id content_favorites.dashboard.content_metadata_id = content_metadata.id content_favorites.dashboard.folder.content_metadata_id = content_metadata.id content_favorites.dashboard.space.content_metadata_id = content_metadata.id content_favorites.look.content_metadata_id = content_metadata.id content_favorites.content_metadata_id = content_metadata.parent_id content_favorites.dashboard.content_metadata_id = content_metadata.parent_id content_favorites.dashboard.folder.content_metadata_id = content_metadata.parent_id content_favorites.dashboard.space.content_metadata_id = content_metadata.parent_id content_favorites.look.content_metadata_id = content_metadata.parent_id content_favorites.dashboard.id = content_metadata.dashboard_id content_favorites.dashboard_id = content_metadata.dashboard_id content_favorites.look_id = content_metadata.look_id content_favorites.look.id = content_metadata.look_id content_favorites.dashboard.space.id = content_metadata.space_id content_favorites.dashboard.space.parent_id = content_metadata.space_id |
| content_metadata_access |
content_favorites.content_metadata_id = content_metadata_access.content_metadata_id content_favorites.dashboard.content_metadata_id = content_metadata_access.content_metadata_id content_favorites.dashboard.folder.content_metadata_id = content_metadata_access.content_metadata_id content_favorites.dashboard.space.content_metadata_id = content_metadata_access.content_metadata_id content_favorites.look.content_metadata_id = content_metadata_access.content_metadata_id |
| content_views |
content_favorites.content_metadata_id = content_views.content_metadata_id content_favorites.dashboard.content_metadata_id = content_views.content_metadata_id content_favorites.dashboard.folder.content_metadata_id = content_views.content_metadata_id content_favorites.dashboard.space.content_metadata_id = content_views.content_metadata_id content_favorites.look.content_metadata_id = content_views.content_metadata_id content_favorites.dashboard.id = content_views.dashboard_id content_favorites.dashboard_id = content_views.dashboard_id content_favorites.look_id = content_views.look_id content_favorites.look.id = content_views.look_id content_favorites.dashboard.folder.creator_id = content_views.user_id content_favorites.dashboard.space.creator_id = content_views.user_id content_favorites.user_id = content_views.user_id |
| dashboard_filters |
content_favorites.dashboard.id = dashboard_filters.dashboard_id content_favorites.dashboard_id = dashboard_filters.dashboard_id |
| dashboard_layouts |
content_favorites.dashboard.id = dashboard_layouts.dashboard_id content_favorites.dashboard_id = dashboard_layouts.dashboard_id |
| scheduled_plans |
content_favorites.dashboard.id = scheduled_plans.dashboard_id content_favorites.dashboard_id = scheduled_plans.dashboard_id content_favorites.look_id = scheduled_plans.look_id content_favorites.look.id = scheduled_plans.look_id content_favorites.dashboard.folder.creator_id = scheduled_plans.user.id content_favorites.dashboard.space.creator_id = scheduled_plans.user.id content_favorites.user_id = scheduled_plans.user.id content_favorites.dashboard.folder.creator_id = scheduled_plans.user_id content_favorites.dashboard.space.creator_id = scheduled_plans.user_id content_favorites.user_id = scheduled_plans.user_id |
| users |
content_favorites.dashboard.folder.id = users.home_folder_id content_favorites.dashboard.folder.parent_id = users.home_folder_id content_favorites.dashboard.folder.id = users.personal_folder_id content_favorites.dashboard.folder.parent_id = users.personal_folder_id content_favorites.dashboard.space.id = users.home_space_id content_favorites.dashboard.space.parent_id = users.home_space_id content_favorites.dashboard.space.id = users.personal_space_id content_favorites.dashboard.space.parent_id = users.personal_space_id content_favorites.dashboard.folder.creator_id = users.id content_favorites.dashboard.space.creator_id = users.id content_favorites.user_id = users.id |
| roles |
content_favorites.dashboard.model.id = roles.model_set.models |
| connections |
content_favorites.dashboard.folder.creator_id = connections.user_id content_favorites.dashboard.space.creator_id = connections.user_id content_favorites.user_id = connections.user_id |
| user_login_lockouts |
content_favorites.dashboard.folder.creator_id = user_login_lockouts.user_id content_favorites.dashboard.space.creator_id = user_login_lockouts.user_id content_favorites.user_id = user_login_lockouts.user_id |
|
content_metadata_id STRING |
||||||||||||||||||||||||||||||||||||||||||||
|
dashboard OBJECT
|
||||||||||||||||||||||||||||||||||||||||||||
|
dashboard_id STRING |
||||||||||||||||||||||||||||||||||||||||||||
|
id
STRING |
||||||||||||||||||||||||||||||||||||||||||||
|
look OBJECT
|
||||||||||||||||||||||||||||||||||||||||||||
|
look_id STRING |
||||||||||||||||||||||||||||||||||||||||||||
|
user_id STRING |
content_metadata
The content_metadata table contains information about content metadata in your Looker instance.
|
Full Table |
|
|
Primary Key |
id |
| Useful links |
| Join content_metadata with | on |
|---|---|
| content_favorites |
content_metadata.id = content_favorites.content_metadata_id content_metadata.parent_id = content_favorites.content_metadata_id content_metadata.id = content_favorites.dashboard.content_metadata_id content_metadata.parent_id = content_favorites.dashboard.content_metadata_id content_metadata.id = content_favorites.dashboard.folder.content_metadata_id content_metadata.parent_id = content_favorites.dashboard.folder.content_metadata_id content_metadata.id = content_favorites.dashboard.space.content_metadata_id content_metadata.parent_id = content_favorites.dashboard.space.content_metadata_id content_metadata.id = content_favorites.look.content_metadata_id content_metadata.parent_id = content_favorites.look.content_metadata_id content_metadata.dashboard_id = content_favorites.dashboard.id content_metadata.dashboard_id = content_favorites.dashboard_id content_metadata.look_id = content_favorites.look_id content_metadata.look_id = content_favorites.look.id content_metadata.space_id = content_favorites.dashboard.space.id content_metadata.space_id = content_favorites.dashboard.space.parent_id |
| content_metadata_access |
content_metadata.id = content_metadata_access.content_metadata_id content_metadata.parent_id = content_metadata_access.content_metadata_id |
| content_views |
content_metadata.id = content_views.content_metadata_id content_metadata.parent_id = content_views.content_metadata_id content_metadata.dashboard_id = content_views.dashboard_id content_metadata.look_id = content_views.look_id |
| dashboard_elements |
content_metadata.id = dashboard_elements.look.content_metadata_id content_metadata.parent_id = dashboard_elements.look.content_metadata_id content_metadata.id = dashboard_elements.look.folder.content_metadata_id content_metadata.parent_id = dashboard_elements.look.folder.content_metadata_id content_metadata.id = dashboard_elements.look.space.content_metadata_id content_metadata.parent_id = dashboard_elements.look.space.content_metadata_id content_metadata.dashboard_id = dashboard_elements.dashboard_id content_metadata.look_id = dashboard_elements.look.id content_metadata.look_id = dashboard_elements.look_id content_metadata.space_id = dashboard_elements.look.space.id content_metadata.space_id = dashboard_elements.look.space.parent_id |
| dashboards |
content_metadata.id = dashboards.content_metadata_id content_metadata.parent_id = dashboards.content_metadata_id content_metadata.id = dashboards.folder.content_metadata_id content_metadata.parent_id = dashboards.folder.content_metadata_id content_metadata.id = dashboards.space.content_metadata_id content_metadata.parent_id = dashboards.space.content_metadata_id content_metadata.dashboard_id = dashboards.id content_metadata.space_id = dashboards.space.id content_metadata.space_id = dashboards.space.parent_id |
| folders |
content_metadata.id = folders.dashboards.folder.content_metadata_id content_metadata.parent_id = folders.dashboards.folder.content_metadata_id content_metadata.id = folders.dashboards.space.content_metadata_id content_metadata.parent_id = folders.dashboards.space.content_metadata_id content_metadata.id = folders.looks.content_metadata_id content_metadata.parent_id = folders.looks.content_metadata_id content_metadata.id = folders.looks.folder.content_metadata_id content_metadata.parent_id = folders.looks.folder.content_metadata_id content_metadata.dashboard_id = folders.dashboards.id content_metadata.look_id = folders.looks.id content_metadata.space_id = folders.dashboards.space.id content_metadata.space_id = folders.dashboards.space.parent_id content_metadata.space_id = folders.looks.space.id content_metadata.space_id = folders.looks.space.parent_id content_metadata.space_id = folders.looks.space_id |
| lookml_dashboards |
content_metadata.id = lookml_dashboards.content_metadata_id content_metadata.parent_id = lookml_dashboards.content_metadata_id content_metadata.id = lookml_dashboards.folder.content_metadata_id content_metadata.parent_id = lookml_dashboards.folder.content_metadata_id content_metadata.id = lookml_dashboards.space.content_metadata_id content_metadata.parent_id = lookml_dashboards.space.content_metadata_id content_metadata.space_id = lookml_dashboards.space.id content_metadata.space_id = lookml_dashboards.space.parent_id |
| looks |
content_metadata.id = looks.content_metadata_id content_metadata.parent_id = looks.content_metadata_id content_metadata.look_id = looks.id content_metadata.space_id = looks.space.id content_metadata.space_id = looks.space.parent_id content_metadata.space_id = looks.space_id |
| dashboard_filters |
content_metadata.dashboard_id = dashboard_filters.dashboard_id |
| dashboard_layouts |
content_metadata.dashboard_id = dashboard_layouts.dashboard_id |
| scheduled_plans |
content_metadata.dashboard_id = scheduled_plans.dashboard_id content_metadata.look_id = scheduled_plans.look_id |
| users |
content_metadata.space_id = users.home_space_id content_metadata.space_id = users.personal_space_id |
|
content_type STRING |
|
dashboard_id STRING |
|
folder_id STRING |
|
id
STRING |
|
inheriting_id STRING |
|
inherits BOOLEAN |
|
look_id STRING |
|
name STRING |
|
parent_id STRING |
|
slug STRING |
|
space_id STRING |
content_metadata_access
The content_metadata_access table contains information about content metadata access records in your Looker instance.
|
Full Table |
|
|
Primary Key |
id |
| Useful links |
| Join content_metadata_access with | on |
|---|---|
| content_favorites |
content_metadata_access.content_metadata_id = content_favorites.content_metadata_id content_metadata_access.content_metadata_id = content_favorites.dashboard.content_metadata_id content_metadata_access.content_metadata_id = content_favorites.dashboard.folder.content_metadata_id content_metadata_access.content_metadata_id = content_favorites.dashboard.space.content_metadata_id content_metadata_access.content_metadata_id = content_favorites.look.content_metadata_id |
| content_metadata |
content_metadata_access.content_metadata_id = content_metadata.id content_metadata_access.content_metadata_id = content_metadata.parent_id |
| content_views |
content_metadata_access.content_metadata_id = content_views.content_metadata_id content_metadata_access.group_id = content_views.group_id |
| dashboard_elements |
content_metadata_access.content_metadata_id = dashboard_elements.look.content_metadata_id content_metadata_access.content_metadata_id = dashboard_elements.look.folder.content_metadata_id content_metadata_access.content_metadata_id = dashboard_elements.look.space.content_metadata_id |
| dashboards |
content_metadata_access.content_metadata_id = dashboards.content_metadata_id content_metadata_access.content_metadata_id = dashboards.folder.content_metadata_id content_metadata_access.content_metadata_id = dashboards.space.content_metadata_id |
| folders |
content_metadata_access.content_metadata_id = folders.dashboards.folder.content_metadata_id content_metadata_access.content_metadata_id = folders.dashboards.space.content_metadata_id content_metadata_access.content_metadata_id = folders.looks.content_metadata_id content_metadata_access.content_metadata_id = folders.looks.folder.content_metadata_id |
| lookml_dashboards |
content_metadata_access.content_metadata_id = lookml_dashboards.content_metadata_id content_metadata_access.content_metadata_id = lookml_dashboards.folder.content_metadata_id content_metadata_access.content_metadata_id = lookml_dashboards.space.content_metadata_id |
| looks |
content_metadata_access.content_metadata_id = looks.content_metadata_id |
| groups |
content_metadata_access.group_id = groups.id |
| groups_in_group |
content_metadata_access.group_id = groups_in_group.id content_metadata_access.group_id = groups_in_group.parent_group_id |
| user_attribute_group_values |
content_metadata_access.group_id = user_attribute_group_values.group_id |
| users |
content_metadata_access.group_id = users.group_ids |
|
content_metadata_id STRING |
|
group_id STRING |
|
id
STRING |
|
permission_type STRING |
|
user_id STRING |
content_views
The content_views table contains info about user content views recorded in your Looker instance.
|
Full Table |
|
|
Primary Key |
id |
| Useful links |
| Join content_views with | on |
|---|---|
| content_favorites |
content_views.content_metadata_id = content_favorites.content_metadata_id content_views.content_metadata_id = content_favorites.dashboard.content_metadata_id content_views.content_metadata_id = content_favorites.dashboard.folder.content_metadata_id content_views.content_metadata_id = content_favorites.dashboard.space.content_metadata_id content_views.content_metadata_id = content_favorites.look.content_metadata_id content_views.dashboard_id = content_favorites.dashboard.id content_views.dashboard_id = content_favorites.dashboard_id content_views.look_id = content_favorites.look_id content_views.look_id = content_favorites.look.id content_views.user_id = content_favorites.dashboard.folder.creator_id content_views.user_id = content_favorites.dashboard.space.creator_id content_views.user_id = content_favorites.user_id |
| content_metadata |
content_views.content_metadata_id = content_metadata.id content_views.content_metadata_id = content_metadata.parent_id content_views.dashboard_id = content_metadata.dashboard_id content_views.look_id = content_metadata.look_id |
| content_metadata_access |
content_views.content_metadata_id = content_metadata_access.content_metadata_id content_views.group_id = content_metadata_access.group_id |
| dashboard_elements |
content_views.content_metadata_id = dashboard_elements.look.content_metadata_id content_views.content_metadata_id = dashboard_elements.look.folder.content_metadata_id content_views.content_metadata_id = dashboard_elements.look.space.content_metadata_id content_views.dashboard_id = dashboard_elements.dashboard_id content_views.look_id = dashboard_elements.look.id content_views.look_id = dashboard_elements.look_id content_views.user_id = dashboard_elements.look.deleter_id content_views.user_id = dashboard_elements.look.folder.creator_id content_views.user_id = dashboard_elements.look.last_updater_id content_views.user_id = dashboard_elements.look.space.creator_id content_views.user_id = dashboard_elements.look.user.id content_views.user_id = dashboard_elements.look.user_id |
| dashboards |
content_views.content_metadata_id = dashboards.content_metadata_id content_views.content_metadata_id = dashboards.folder.content_metadata_id content_views.content_metadata_id = dashboards.space.content_metadata_id content_views.dashboard_id = dashboards.id content_views.user_id = dashboards.space.creator_id content_views.user_id = dashboards.user_id |
| folders |
content_views.content_metadata_id = folders.dashboards.folder.content_metadata_id content_views.content_metadata_id = folders.dashboards.space.content_metadata_id content_views.content_metadata_id = folders.looks.content_metadata_id content_views.content_metadata_id = folders.looks.folder.content_metadata_id content_views.dashboard_id = folders.dashboards.id content_views.look_id = folders.looks.id content_views.user_id = folders.creator_id content_views.user_id = folders.dashboards.user_id content_views.user_id = folders.dashboards.folder.creator_id content_views.user_id = folders.dashboards.space.creator_id content_views.user_id = folders.looks.deleter_id content_views.user_id = folders.looks.last_updater_id content_views.user_id = folders.looks.user.id |
| lookml_dashboards |
content_views.content_metadata_id = lookml_dashboards.content_metadata_id content_views.content_metadata_id = lookml_dashboards.folder.content_metadata_id content_views.content_metadata_id = lookml_dashboards.space.content_metadata_id content_views.user_id = lookml_dashboards.folder.creator_id content_views.user_id = lookml_dashboards.space.creator_id content_views.user_id = lookml_dashboards.user_id |
| looks |
content_views.content_metadata_id = looks.content_metadata_id content_views.look_id = looks.id content_views.user_id = looks.deleter_id content_views.user_id = looks.folder.creator_id content_views.user_id = looks.user.id content_views.user_id = looks.user_id |
| dashboard_filters |
content_views.dashboard_id = dashboard_filters.dashboard_id |
| dashboard_layouts |
content_views.dashboard_id = dashboard_layouts.dashboard_id |
| scheduled_plans |
content_views.dashboard_id = scheduled_plans.dashboard_id content_views.look_id = scheduled_plans.look_id content_views.user_id = scheduled_plans.user.id content_views.user_id = scheduled_plans.user_id |
| groups |
content_views.group_id = groups.id |
| groups_in_group |
content_views.group_id = groups_in_group.id content_views.group_id = groups_in_group.parent_group_id |
| user_attribute_group_values |
content_views.group_id = user_attribute_group_values.group_id |
| users |
content_views.group_id = users.group_ids content_views.user_id = users.id |
| connections |
content_views.user_id = connections.user_id |
| user_login_lockouts |
content_views.user_id = user_login_lockouts.user_id |
|
content_metadata_id STRING |
|
dashboard_id STRING |
|
favorite_count INTEGER |
|
group_id STRING |
|
id
STRING |
|
last_viewed_at STRING |
|
look_id STRING |
|
start_of_week_date STRING |
|
user_id STRING |
|
view_count INTEGER |
dashboard_elements
The dashboard_elements table contains information about all dashboard elements in your Looker instance.
|
Full Table |
|
|
Primary Key |
id |
| Useful links |
| Join dashboard_elements with | on |
|---|---|
| content_favorites |
dashboard_elements.look.content_favorite_id = content_favorites.id dashboard_elements.look.content_favorite_id = content_favorites.dashboard.content_favorite_id dashboard_elements.look.content_metadata_id = content_favorites.content_metadata_id dashboard_elements.look.folder.content_metadata_id = content_favorites.content_metadata_id dashboard_elements.look.space.content_metadata_id = content_favorites.content_metadata_id dashboard_elements.look.content_metadata_id = content_favorites.dashboard.content_metadata_id dashboard_elements.look.folder.content_metadata_id = content_favorites.dashboard.content_metadata_id dashboard_elements.look.space.content_metadata_id = content_favorites.dashboard.content_metadata_id dashboard_elements.look.content_metadata_id = content_favorites.dashboard.folder.content_metadata_id dashboard_elements.look.folder.content_metadata_id = content_favorites.dashboard.folder.content_metadata_id dashboard_elements.look.space.content_metadata_id = content_favorites.dashboard.folder.content_metadata_id dashboard_elements.look.content_metadata_id = content_favorites.dashboard.space.content_metadata_id dashboard_elements.look.folder.content_metadata_id = content_favorites.dashboard.space.content_metadata_id dashboard_elements.look.space.content_metadata_id = content_favorites.dashboard.space.content_metadata_id dashboard_elements.look.content_metadata_id = content_favorites.look.content_metadata_id dashboard_elements.look.folder.content_metadata_id = content_favorites.look.content_metadata_id dashboard_elements.look.space.content_metadata_id = content_favorites.look.content_metadata_id dashboard_elements.dashboard_id = content_favorites.dashboard.id dashboard_elements.dashboard_id = content_favorites.dashboard_id dashboard_elements.look.folder.id = content_favorites.dashboard.folder.id dashboard_elements.look.folder.parent_id = content_favorites.dashboard.folder.id dashboard_elements.look.folder_id = content_favorites.dashboard.folder.id dashboard_elements.look.folder.id = content_favorites.dashboard.folder.parent_id dashboard_elements.look.folder.parent_id = content_favorites.dashboard.folder.parent_id dashboard_elements.look.folder_id = content_favorites.dashboard.folder.parent_id dashboard_elements.look.id = content_favorites.look_id dashboard_elements.look_id = content_favorites.look_id dashboard_elements.look.id = content_favorites.look.id dashboard_elements.look_id = content_favorites.look.id dashboard_elements.look.model.id = content_favorites.dashboard.model.id dashboard_elements.look.space.id = content_favorites.dashboard.space.id dashboard_elements.look.space.parent_id = content_favorites.dashboard.space.id dashboard_elements.look.space.id = content_favorites.dashboard.space.parent_id dashboard_elements.look.space.parent_id = content_favorites.dashboard.space.parent_id dashboard_elements.look.deleter_id = content_favorites.dashboard.folder.creator_id dashboard_elements.look.folder.creator_id = content_favorites.dashboard.folder.creator_id dashboard_elements.look.last_updater_id = content_favorites.dashboard.folder.creator_id dashboard_elements.look.space.creator_id = content_favorites.dashboard.folder.creator_id dashboard_elements.look.user.id = content_favorites.dashboard.folder.creator_id dashboard_elements.look.user_id = content_favorites.dashboard.folder.creator_id dashboard_elements.look.deleter_id = content_favorites.dashboard.space.creator_id dashboard_elements.look.folder.creator_id = content_favorites.dashboard.space.creator_id dashboard_elements.look.last_updater_id = content_favorites.dashboard.space.creator_id dashboard_elements.look.space.creator_id = content_favorites.dashboard.space.creator_id dashboard_elements.look.user.id = content_favorites.dashboard.space.creator_id dashboard_elements.look.user_id = content_favorites.dashboard.space.creator_id dashboard_elements.look.deleter_id = content_favorites.user_id dashboard_elements.look.folder.creator_id = content_favorites.user_id dashboard_elements.look.last_updater_id = content_favorites.user_id dashboard_elements.look.space.creator_id = content_favorites.user_id dashboard_elements.look.user.id = content_favorites.user_id dashboard_elements.look.user_id = content_favorites.user_id |
| dashboards |
dashboard_elements.look.content_favorite_id = dashboards.content_favorite_id dashboard_elements.look.content_metadata_id = dashboards.content_metadata_id dashboard_elements.look.folder.content_metadata_id = dashboards.content_metadata_id dashboard_elements.look.space.content_metadata_id = dashboards.content_metadata_id dashboard_elements.look.content_metadata_id = dashboards.folder.content_metadata_id dashboard_elements.look.folder.content_metadata_id = dashboards.folder.content_metadata_id dashboard_elements.look.space.content_metadata_id = dashboards.folder.content_metadata_id dashboard_elements.look.content_metadata_id = dashboards.space.content_metadata_id dashboard_elements.look.folder.content_metadata_id = dashboards.space.content_metadata_id dashboard_elements.look.space.content_metadata_id = dashboards.space.content_metadata_id dashboard_elements.dashboard_id = dashboards.id dashboard_elements.look.folder.id = dashboards.folder.id dashboard_elements.look.folder.parent_id = dashboards.folder.id dashboard_elements.look.folder_id = dashboards.folder.id dashboard_elements.look.folder.id = dashboards.folder.parent_id dashboard_elements.look.folder.parent_id = dashboards.folder.parent_id dashboard_elements.look.folder_id = dashboards.folder.parent_id dashboard_elements.look.model.id = dashboards.model.id dashboard_elements.look.space.id = dashboards.space.id dashboard_elements.look.space.parent_id = dashboards.space.id dashboard_elements.look.space.id = dashboards.space.parent_id dashboard_elements.look.space.parent_id = dashboards.space.parent_id dashboard_elements.look.deleter_id = dashboards.space.creator_id dashboard_elements.look.folder.creator_id = dashboards.space.creator_id dashboard_elements.look.last_updater_id = dashboards.space.creator_id dashboard_elements.look.space.creator_id = dashboards.space.creator_id dashboard_elements.look.user.id = dashboards.space.creator_id dashboard_elements.look.user_id = dashboards.space.creator_id dashboard_elements.look.deleter_id = dashboards.user_id dashboard_elements.look.folder.creator_id = dashboards.user_id dashboard_elements.look.last_updater_id = dashboards.user_id dashboard_elements.look.space.creator_id = dashboards.user_id dashboard_elements.look.user.id = dashboards.user_id dashboard_elements.look.user_id = dashboards.user_id |
| folders |
dashboard_elements.look.content_favorite_id = folders.dashboards.content_favorite_id dashboard_elements.look.content_favorite_id = folders.looks.content_favorite_id dashboard_elements.look.content_metadata_id = folders.dashboards.folder.content_metadata_id dashboard_elements.look.folder.content_metadata_id = folders.dashboards.folder.content_metadata_id dashboard_elements.look.space.content_metadata_id = folders.dashboards.folder.content_metadata_id dashboard_elements.look.content_metadata_id = folders.dashboards.space.content_metadata_id dashboard_elements.look.folder.content_metadata_id = folders.dashboards.space.content_metadata_id dashboard_elements.look.space.content_metadata_id = folders.dashboards.space.content_metadata_id dashboard_elements.look.content_metadata_id = folders.looks.content_metadata_id dashboard_elements.look.folder.content_metadata_id = folders.looks.content_metadata_id dashboard_elements.look.space.content_metadata_id = folders.looks.content_metadata_id dashboard_elements.look.content_metadata_id = folders.looks.folder.content_metadata_id dashboard_elements.look.folder.content_metadata_id = folders.looks.folder.content_metadata_id dashboard_elements.look.space.content_metadata_id = folders.looks.folder.content_metadata_id dashboard_elements.dashboard_id = folders.dashboards.id dashboard_elements.look.folder.id = folders.id dashboard_elements.look.folder.parent_id = folders.id dashboard_elements.look.folder_id = folders.id dashboard_elements.look.folder.id = folders.dashboards.folder.id dashboard_elements.look.folder.parent_id = folders.dashboards.folder.id dashboard_elements.look.folder_id = folders.dashboards.folder.id dashboard_elements.look.folder.id = folders.dashboards.folder.parent_id dashboard_elements.look.folder.parent_id = folders.dashboards.folder.parent_id dashboard_elements.look.folder_id = folders.dashboards.folder.parent_id dashboard_elements.look.folder.id = folders.looks.folder.id dashboard_elements.look.folder.parent_id = folders.looks.folder.id dashboard_elements.look.folder_id = folders.looks.folder.id dashboard_elements.look.folder.id = folders.looks.folder.parent_id dashboard_elements.look.folder.parent_id = folders.looks.folder.parent_id dashboard_elements.look.folder_id = folders.looks.folder.parent_id dashboard_elements.look.folder.id = folders.parent_id dashboard_elements.look.folder.parent_id = folders.parent_id dashboard_elements.look.folder_id = folders.parent_id dashboard_elements.look.id = folders.looks.id dashboard_elements.look_id = folders.looks.id dashboard_elements.look.model.id = folders.dashboards.model.id dashboard_elements.look.model.id = folders.looks.model.id dashboard_elements.look.query.id = folders.looks.query_id dashboard_elements.look.query_id = folders.looks.query_id dashboard_elements.query.id = folders.looks.query_id dashboard_elements.query_id = folders.looks.query_id dashboard_elements.result_maker.query.id = folders.looks.query_id dashboard_elements.result_maker.query_id = folders.looks.query_id dashboard_elements.look.space.id = folders.dashboards.space.id dashboard_elements.look.space.parent_id = folders.dashboards.space.id dashboard_elements.look.space.id = folders.dashboards.space.parent_id dashboard_elements.look.space.parent_id = folders.dashboards.space.parent_id dashboard_elements.look.space.id = folders.looks.space.id dashboard_elements.look.space.parent_id = folders.looks.space.id dashboard_elements.look.space.id = folders.looks.space.parent_id dashboard_elements.look.space.parent_id = folders.looks.space.parent_id dashboard_elements.look.space.id = folders.looks.space_id dashboard_elements.look.space.parent_id = folders.looks.space_id dashboard_elements.look.deleter_id = folders.creator_id dashboard_elements.look.folder.creator_id = folders.creator_id dashboard_elements.look.last_updater_id = folders.creator_id dashboard_elements.look.space.creator_id = folders.creator_id dashboard_elements.look.user.id = folders.creator_id dashboard_elements.look.user_id = folders.creator_id dashboard_elements.look.deleter_id = folders.dashboards.user_id dashboard_elements.look.folder.creator_id = folders.dashboards.user_id dashboard_elements.look.last_updater_id = folders.dashboards.user_id dashboard_elements.look.space.creator_id = folders.dashboards.user_id dashboard_elements.look.user.id = folders.dashboards.user_id dashboard_elements.look.user_id = folders.dashboards.user_id dashboard_elements.look.deleter_id = folders.dashboards.folder.creator_id dashboard_elements.look.folder.creator_id = folders.dashboards.folder.creator_id dashboard_elements.look.last_updater_id = folders.dashboards.folder.creator_id dashboard_elements.look.space.creator_id = folders.dashboards.folder.creator_id dashboard_elements.look.user.id = folders.dashboards.folder.creator_id dashboard_elements.look.user_id = folders.dashboards.folder.creator_id dashboard_elements.look.deleter_id = folders.dashboards.space.creator_id dashboard_elements.look.folder.creator_id = folders.dashboards.space.creator_id dashboard_elements.look.last_updater_id = folders.dashboards.space.creator_id dashboard_elements.look.space.creator_id = folders.dashboards.space.creator_id dashboard_elements.look.user.id = folders.dashboards.space.creator_id dashboard_elements.look.user_id = folders.dashboards.space.creator_id dashboard_elements.look.deleter_id = folders.looks.deleter_id dashboard_elements.look.folder.creator_id = folders.looks.deleter_id dashboard_elements.look.last_updater_id = folders.looks.deleter_id dashboard_elements.look.space.creator_id = folders.looks.deleter_id dashboard_elements.look.user.id = folders.looks.deleter_id dashboard_elements.look.user_id = folders.looks.deleter_id dashboard_elements.look.deleter_id = folders.looks.last_updater_id dashboard_elements.look.folder.creator_id = folders.looks.last_updater_id dashboard_elements.look.last_updater_id = folders.looks.last_updater_id dashboard_elements.look.space.creator_id = folders.looks.last_updater_id dashboard_elements.look.user.id = folders.looks.last_updater_id dashboard_elements.look.user_id = folders.looks.last_updater_id dashboard_elements.look.deleter_id = folders.looks.user.id dashboard_elements.look.folder.creator_id = folders.looks.user.id dashboard_elements.look.last_updater_id = folders.looks.user.id dashboard_elements.look.space.creator_id = folders.looks.user.id dashboard_elements.look.user.id = folders.looks.user.id dashboard_elements.look.user_id = folders.looks.user.id |
| lookml_dashboards |
dashboard_elements.look.content_favorite_id = lookml_dashboards.content_favorite_id dashboard_elements.look.content_metadata_id = lookml_dashboards.content_metadata_id dashboard_elements.look.folder.content_metadata_id = lookml_dashboards.content_metadata_id dashboard_elements.look.space.content_metadata_id = lookml_dashboards.content_metadata_id dashboard_elements.look.content_metadata_id = lookml_dashboards.folder.content_metadata_id dashboard_elements.look.folder.content_metadata_id = lookml_dashboards.folder.content_metadata_id dashboard_elements.look.space.content_metadata_id = lookml_dashboards.folder.content_metadata_id dashboard_elements.look.content_metadata_id = lookml_dashboards.space.content_metadata_id dashboard_elements.look.folder.content_metadata_id = lookml_dashboards.space.content_metadata_id dashboard_elements.look.space.content_metadata_id = lookml_dashboards.space.content_metadata_id dashboard_elements.look.folder.id = lookml_dashboards.folder.id dashboard_elements.look.folder.parent_id = lookml_dashboards.folder.id dashboard_elements.look.folder_id = lookml_dashboards.folder.id dashboard_elements.look.folder.id = lookml_dashboards.folder.parent_id dashboard_elements.look.folder.parent_id = lookml_dashboards.folder.parent_id dashboard_elements.look.folder_id = lookml_dashboards.folder.parent_id dashboard_elements.look.model.id = lookml_dashboards.model.id dashboard_elements.look.space.id = lookml_dashboards.space.id dashboard_elements.look.space.parent_id = lookml_dashboards.space.id dashboard_elements.look.space.id = lookml_dashboards.space.parent_id dashboard_elements.look.space.parent_id = lookml_dashboards.space.parent_id dashboard_elements.look.deleter_id = lookml_dashboards.folder.creator_id dashboard_elements.look.folder.creator_id = lookml_dashboards.folder.creator_id dashboard_elements.look.last_updater_id = lookml_dashboards.folder.creator_id dashboard_elements.look.space.creator_id = lookml_dashboards.folder.creator_id dashboard_elements.look.user.id = lookml_dashboards.folder.creator_id dashboard_elements.look.user_id = lookml_dashboards.folder.creator_id dashboard_elements.look.deleter_id = lookml_dashboards.space.creator_id dashboard_elements.look.folder.creator_id = lookml_dashboards.space.creator_id dashboard_elements.look.last_updater_id = lookml_dashboards.space.creator_id dashboard_elements.look.space.creator_id = lookml_dashboards.space.creator_id dashboard_elements.look.user.id = lookml_dashboards.space.creator_id dashboard_elements.look.user_id = lookml_dashboards.space.creator_id dashboard_elements.look.deleter_id = lookml_dashboards.user_id dashboard_elements.look.folder.creator_id = lookml_dashboards.user_id dashboard_elements.look.last_updater_id = lookml_dashboards.user_id dashboard_elements.look.space.creator_id = lookml_dashboards.user_id dashboard_elements.look.user.id = lookml_dashboards.user_id dashboard_elements.look.user_id = lookml_dashboards.user_id |
| looks |
dashboard_elements.look.content_favorite_id = looks.content_favorite_id dashboard_elements.look.content_metadata_id = looks.content_metadata_id dashboard_elements.look.folder.content_metadata_id = looks.content_metadata_id dashboard_elements.look.space.content_metadata_id = looks.content_metadata_id dashboard_elements.look.folder.id = looks.folder.id dashboard_elements.look.folder.parent_id = looks.folder.id dashboard_elements.look.folder_id = looks.folder.id dashboard_elements.look.folder.id = looks.folder_id dashboard_elements.look.folder.parent_id = looks.folder_id dashboard_elements.look.folder_id = looks.folder_id dashboard_elements.look.folder.id = looks.folder.parent_id dashboard_elements.look.folder.parent_id = looks.folder.parent_id dashboard_elements.look.folder_id = looks.folder.parent_id dashboard_elements.look.id = looks.id dashboard_elements.look_id = looks.id dashboard_elements.look.model.id = looks.model.id dashboard_elements.look.query.id = looks.query_id dashboard_elements.look.query_id = looks.query_id dashboard_elements.query.id = looks.query_id dashboard_elements.query_id = looks.query_id dashboard_elements.result_maker.query.id = looks.query_id dashboard_elements.result_maker.query_id = looks.query_id dashboard_elements.look.space.id = looks.space.id dashboard_elements.look.space.parent_id = looks.space.id dashboard_elements.look.space.id = looks.space.parent_id dashboard_elements.look.space.parent_id = looks.space.parent_id dashboard_elements.look.space.id = looks.space_id dashboard_elements.look.space.parent_id = looks.space_id dashboard_elements.look.deleter_id = looks.deleter_id dashboard_elements.look.folder.creator_id = looks.deleter_id dashboard_elements.look.last_updater_id = looks.deleter_id dashboard_elements.look.space.creator_id = looks.deleter_id dashboard_elements.look.user.id = looks.deleter_id dashboard_elements.look.user_id = looks.deleter_id dashboard_elements.look.deleter_id = looks.folder.creator_id dashboard_elements.look.folder.creator_id = looks.folder.creator_id dashboard_elements.look.last_updater_id = looks.folder.creator_id dashboard_elements.look.space.creator_id = looks.folder.creator_id dashboard_elements.look.user.id = looks.folder.creator_id dashboard_elements.look.user_id = looks.folder.creator_id dashboard_elements.look.deleter_id = looks.user.id dashboard_elements.look.folder.creator_id = looks.user.id dashboard_elements.look.last_updater_id = looks.user.id dashboard_elements.look.space.creator_id = looks.user.id dashboard_elements.look.user.id = looks.user.id dashboard_elements.look.user_id = looks.user.id dashboard_elements.look.deleter_id = looks.user_id dashboard_elements.look.folder.creator_id = looks.user_id dashboard_elements.look.last_updater_id = looks.user_id dashboard_elements.look.space.creator_id = looks.user_id dashboard_elements.look.user.id = looks.user_id dashboard_elements.look.user_id = looks.user_id |
| content_metadata |
dashboard_elements.look.content_metadata_id = content_metadata.id dashboard_elements.look.folder.content_metadata_id = content_metadata.id dashboard_elements.look.space.content_metadata_id = content_metadata.id dashboard_elements.look.content_metadata_id = content_metadata.parent_id dashboard_elements.look.folder.content_metadata_id = content_metadata.parent_id dashboard_elements.look.space.content_metadata_id = content_metadata.parent_id dashboard_elements.dashboard_id = content_metadata.dashboard_id dashboard_elements.look.id = content_metadata.look_id dashboard_elements.look_id = content_metadata.look_id dashboard_elements.look.space.id = content_metadata.space_id dashboard_elements.look.space.parent_id = content_metadata.space_id |
| content_metadata_access |
dashboard_elements.look.content_metadata_id = content_metadata_access.content_metadata_id dashboard_elements.look.folder.content_metadata_id = content_metadata_access.content_metadata_id dashboard_elements.look.space.content_metadata_id = content_metadata_access.content_metadata_id |
| content_views |
dashboard_elements.look.content_metadata_id = content_views.content_metadata_id dashboard_elements.look.folder.content_metadata_id = content_views.content_metadata_id dashboard_elements.look.space.content_metadata_id = content_views.content_metadata_id dashboard_elements.dashboard_id = content_views.dashboard_id dashboard_elements.look.id = content_views.look_id dashboard_elements.look_id = content_views.look_id dashboard_elements.look.deleter_id = content_views.user_id dashboard_elements.look.folder.creator_id = content_views.user_id dashboard_elements.look.last_updater_id = content_views.user_id dashboard_elements.look.space.creator_id = content_views.user_id dashboard_elements.look.user.id = content_views.user_id dashboard_elements.look.user_id = content_views.user_id |
| dashboard_filters |
dashboard_elements.dashboard_id = dashboard_filters.dashboard_id |
| dashboard_layouts |
dashboard_elements.dashboard_id = dashboard_layouts.dashboard_id dashboard_elements.id = dashboard_layouts.dashboard_layout_components.dashboard_element_id |
| scheduled_plans |
dashboard_elements.dashboard_id = scheduled_plans.dashboard_id dashboard_elements.look.id = scheduled_plans.look_id dashboard_elements.look_id = scheduled_plans.look_id dashboard_elements.look.query.id = scheduled_plans.query_id dashboard_elements.look.query_id = scheduled_plans.query_id dashboard_elements.query.id = scheduled_plans.query_id dashboard_elements.query_id = scheduled_plans.query_id dashboard_elements.result_maker.query.id = scheduled_plans.query_id dashboard_elements.result_maker.query_id = scheduled_plans.query_id dashboard_elements.look.deleter_id = scheduled_plans.user.id dashboard_elements.look.folder.creator_id = scheduled_plans.user.id dashboard_elements.look.last_updater_id = scheduled_plans.user.id dashboard_elements.look.space.creator_id = scheduled_plans.user.id dashboard_elements.look.user.id = scheduled_plans.user.id dashboard_elements.look.user_id = scheduled_plans.user.id dashboard_elements.look.deleter_id = scheduled_plans.user_id dashboard_elements.look.folder.creator_id = scheduled_plans.user_id dashboard_elements.look.last_updater_id = scheduled_plans.user_id dashboard_elements.look.space.creator_id = scheduled_plans.user_id dashboard_elements.look.user.id = scheduled_plans.user_id dashboard_elements.look.user_id = scheduled_plans.user_id |
| users |
dashboard_elements.look.folder.id = users.home_folder_id dashboard_elements.look.folder.parent_id = users.home_folder_id dashboard_elements.look.folder_id = users.home_folder_id dashboard_elements.look.folder.id = users.personal_folder_id dashboard_elements.look.folder.parent_id = users.personal_folder_id dashboard_elements.look.folder_id = users.personal_folder_id dashboard_elements.look.space.id = users.home_space_id dashboard_elements.look.space.parent_id = users.home_space_id dashboard_elements.look.space.id = users.personal_space_id dashboard_elements.look.space.parent_id = users.personal_space_id dashboard_elements.look.deleter_id = users.id dashboard_elements.look.folder.creator_id = users.id dashboard_elements.look.last_updater_id = users.id dashboard_elements.look.space.creator_id = users.id dashboard_elements.look.user.id = users.id dashboard_elements.look.user_id = users.id |
| roles |
dashboard_elements.look.model.id = roles.model_set.models |
| queries |
dashboard_elements.look.query.id = queries.id dashboard_elements.look.query_id = queries.id dashboard_elements.query.id = queries.id dashboard_elements.query_id = queries.id dashboard_elements.result_maker.query.id = queries.id dashboard_elements.result_maker.query_id = queries.id |
| connections |
dashboard_elements.look.deleter_id = connections.user_id dashboard_elements.look.folder.creator_id = connections.user_id dashboard_elements.look.last_updater_id = connections.user_id dashboard_elements.look.space.creator_id = connections.user_id dashboard_elements.look.user.id = connections.user_id dashboard_elements.look.user_id = connections.user_id |
| user_login_lockouts |
dashboard_elements.look.deleter_id = user_login_lockouts.user_id dashboard_elements.look.folder.creator_id = user_login_lockouts.user_id dashboard_elements.look.last_updater_id = user_login_lockouts.user_id dashboard_elements.look.space.creator_id = user_login_lockouts.user_id dashboard_elements.look.user.id = user_login_lockouts.user_id dashboard_elements.look.user_id = user_login_lockouts.user_id |
|
alert_count INTEGER |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
body_text STRING |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
body_text_as_html STRING |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
dashboard_id STRING |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
edit_uri STRING |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
id
STRING |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
look OBJECT
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
look_id STRING |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
lookml_link_id STRING |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
merge_result_id STRING |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
note_display STRING |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
note_state STRING |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
note_text STRING |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
note_text_as_html STRING |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
query OBJECT
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
query_id STRING |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
refresh_interval STRING |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
refresh_interval_to_i INTEGER |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
result_maker OBJECT
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
result_maker_id STRING |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
subtitle_text STRING |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
title STRING |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
title_hidden BOOLEAN |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
title_text STRING |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
type STRING |
dashboard_filters
The dashboard_filters table contains information about all dashboard filters in your Looker instance.
|
Full Table |
|
|
Primary Key |
id |
| Useful links |
| Join dashboard_filters with | on |
|---|---|
| content_favorites |
dashboard_filters.dashboard_id = content_favorites.dashboard.id dashboard_filters.dashboard_id = content_favorites.dashboard_id |
| content_metadata |
dashboard_filters.dashboard_id = content_metadata.dashboard_id |
| content_views |
dashboard_filters.dashboard_id = content_views.dashboard_id |
| dashboard_elements |
dashboard_filters.dashboard_id = dashboard_elements.dashboard_id |
| dashboard_layouts |
dashboard_filters.dashboard_id = dashboard_layouts.dashboard_id |
| dashboards |
dashboard_filters.dashboard_id = dashboards.id |
| folders |
dashboard_filters.dashboard_id = folders.dashboards.id |
| scheduled_plans |
dashboard_filters.dashboard_id = scheduled_plans.dashboard_id |
|
allow_multiple_values BOOLEAN |
|
dashboard_id STRING |
|
default_value STRING |
|
dimension STRING |
|
explore STRING |
|
field OBJECT |
|
id
STRING |
|
listens_to_filters ARRAY |
|
model STRING |
|
name STRING |
|
required BOOLEAN |
|
row INTEGER |
|
title STRING |
|
type STRING |
|
ui_config OBJECT |
dashboard_layouts
The dashboard_layouts table contains information about all dashboard layouts in your Looker instance.
|
Full Table |
|
|
Primary Key |
id |
| Useful links |
| Join dashboard_layouts with | on |
|---|---|
| content_favorites |
dashboard_layouts.dashboard_id = content_favorites.dashboard.id dashboard_layouts.dashboard_id = content_favorites.dashboard_id |
| content_metadata |
dashboard_layouts.dashboard_id = content_metadata.dashboard_id |
| content_views |
dashboard_layouts.dashboard_id = content_views.dashboard_id |
| dashboard_elements |
dashboard_layouts.dashboard_id = dashboard_elements.dashboard_id dashboard_layouts.dashboard_layout_components.dashboard_element_id = dashboard_elements.id |
| dashboard_filters |
dashboard_layouts.dashboard_id = dashboard_filters.dashboard_id |
| dashboards |
dashboard_layouts.dashboard_id = dashboards.id |
| folders |
dashboard_layouts.dashboard_id = folders.dashboards.id |
| scheduled_plans |
dashboard_layouts.dashboard_id = scheduled_plans.dashboard_id |
|
active BOOLEAN |
|||||||||||
|
column_width INTEGER |
|||||||||||
|
dashboard_id STRING |
|||||||||||
|
dashboard_layout_components ARRAY
|
|||||||||||
|
dashboard_title STRING |
|||||||||||
|
deleted BOOLEAN |
|||||||||||
|
id
STRING |
|||||||||||
|
type STRING |
|||||||||||
|
width INTEGER |
dashboards
The dashboards table contains information about all active dashboards in your Looker account.
|
Full Table |
|
|
Primary Key |
id |
| Useful links |
| Join dashboards with | on |
|---|---|
| content_favorites |
dashboards.content_favorite_id = content_favorites.id dashboards.content_favorite_id = content_favorites.dashboard.content_favorite_id dashboards.content_metadata_id = content_favorites.content_metadata_id dashboards.folder.content_metadata_id = content_favorites.content_metadata_id dashboards.space.content_metadata_id = content_favorites.content_metadata_id dashboards.content_metadata_id = content_favorites.dashboard.content_metadata_id dashboards.folder.content_metadata_id = content_favorites.dashboard.content_metadata_id dashboards.space.content_metadata_id = content_favorites.dashboard.content_metadata_id dashboards.content_metadata_id = content_favorites.dashboard.folder.content_metadata_id dashboards.folder.content_metadata_id = content_favorites.dashboard.folder.content_metadata_id dashboards.space.content_metadata_id = content_favorites.dashboard.folder.content_metadata_id dashboards.content_metadata_id = content_favorites.dashboard.space.content_metadata_id dashboards.folder.content_metadata_id = content_favorites.dashboard.space.content_metadata_id dashboards.space.content_metadata_id = content_favorites.dashboard.space.content_metadata_id dashboards.content_metadata_id = content_favorites.look.content_metadata_id dashboards.folder.content_metadata_id = content_favorites.look.content_metadata_id dashboards.space.content_metadata_id = content_favorites.look.content_metadata_id dashboards.id = content_favorites.dashboard.id dashboards.id = content_favorites.dashboard_id dashboards.folder.id = content_favorites.dashboard.folder.id dashboards.folder.parent_id = content_favorites.dashboard.folder.id dashboards.folder.id = content_favorites.dashboard.folder.parent_id dashboards.folder.parent_id = content_favorites.dashboard.folder.parent_id dashboards.model.id = content_favorites.dashboard.model.id dashboards.space.id = content_favorites.dashboard.space.id dashboards.space.parent_id = content_favorites.dashboard.space.id dashboards.space.id = content_favorites.dashboard.space.parent_id dashboards.space.parent_id = content_favorites.dashboard.space.parent_id dashboards.space.creator_id = content_favorites.dashboard.folder.creator_id dashboards.user_id = content_favorites.dashboard.folder.creator_id dashboards.space.creator_id = content_favorites.dashboard.space.creator_id dashboards.user_id = content_favorites.dashboard.space.creator_id dashboards.space.creator_id = content_favorites.user_id dashboards.user_id = content_favorites.user_id |
| dashboard_elements |
dashboards.content_favorite_id = dashboard_elements.look.content_favorite_id dashboards.content_metadata_id = dashboard_elements.look.content_metadata_id dashboards.folder.content_metadata_id = dashboard_elements.look.content_metadata_id dashboards.space.content_metadata_id = dashboard_elements.look.content_metadata_id dashboards.content_metadata_id = dashboard_elements.look.folder.content_metadata_id dashboards.folder.content_metadata_id = dashboard_elements.look.folder.content_metadata_id dashboards.space.content_metadata_id = dashboard_elements.look.folder.content_metadata_id dashboards.content_metadata_id = dashboard_elements.look.space.content_metadata_id dashboards.folder.content_metadata_id = dashboard_elements.look.space.content_metadata_id dashboards.space.content_metadata_id = dashboard_elements.look.space.content_metadata_id dashboards.id = dashboard_elements.dashboard_id dashboards.folder.id = dashboard_elements.look.folder.id dashboards.folder.parent_id = dashboard_elements.look.folder.id dashboards.folder.id = dashboard_elements.look.folder.parent_id dashboards.folder.parent_id = dashboard_elements.look.folder.parent_id dashboards.folder.id = dashboard_elements.look.folder_id dashboards.folder.parent_id = dashboard_elements.look.folder_id dashboards.model.id = dashboard_elements.look.model.id dashboards.space.id = dashboard_elements.look.space.id dashboards.space.parent_id = dashboard_elements.look.space.id dashboards.space.id = dashboard_elements.look.space.parent_id dashboards.space.parent_id = dashboard_elements.look.space.parent_id dashboards.space.creator_id = dashboard_elements.look.deleter_id dashboards.user_id = dashboard_elements.look.deleter_id dashboards.space.creator_id = dashboard_elements.look.folder.creator_id dashboards.user_id = dashboard_elements.look.folder.creator_id dashboards.space.creator_id = dashboard_elements.look.last_updater_id dashboards.user_id = dashboard_elements.look.last_updater_id dashboards.space.creator_id = dashboard_elements.look.space.creator_id dashboards.user_id = dashboard_elements.look.space.creator_id dashboards.space.creator_id = dashboard_elements.look.user.id dashboards.user_id = dashboard_elements.look.user.id dashboards.space.creator_id = dashboard_elements.look.user_id dashboards.user_id = dashboard_elements.look.user_id |
| folders |
dashboards.content_favorite_id = folders.dashboards.content_favorite_id dashboards.content_favorite_id = folders.looks.content_favorite_id dashboards.content_metadata_id = folders.dashboards.folder.content_metadata_id dashboards.folder.content_metadata_id = folders.dashboards.folder.content_metadata_id dashboards.space.content_metadata_id = folders.dashboards.folder.content_metadata_id dashboards.content_metadata_id = folders.dashboards.space.content_metadata_id dashboards.folder.content_metadata_id = folders.dashboards.space.content_metadata_id dashboards.space.content_metadata_id = folders.dashboards.space.content_metadata_id dashboards.content_metadata_id = folders.looks.content_metadata_id dashboards.folder.content_metadata_id = folders.looks.content_metadata_id dashboards.space.content_metadata_id = folders.looks.content_metadata_id dashboards.content_metadata_id = folders.looks.folder.content_metadata_id dashboards.folder.content_metadata_id = folders.looks.folder.content_metadata_id dashboards.space.content_metadata_id = folders.looks.folder.content_metadata_id dashboards.id = folders.dashboards.id dashboards.folder.id = folders.id dashboards.folder.parent_id = folders.id dashboards.folder.id = folders.dashboards.folder.id dashboards.folder.parent_id = folders.dashboards.folder.id dashboards.folder.id = folders.dashboards.folder.parent_id dashboards.folder.parent_id = folders.dashboards.folder.parent_id dashboards.folder.id = folders.looks.folder.id dashboards.folder.parent_id = folders.looks.folder.id dashboards.folder.id = folders.looks.folder.parent_id dashboards.folder.parent_id = folders.looks.folder.parent_id dashboards.folder.id = folders.parent_id dashboards.folder.parent_id = folders.parent_id dashboards.model.id = folders.dashboards.model.id dashboards.model.id = folders.looks.model.id dashboards.space.id = folders.dashboards.space.id dashboards.space.parent_id = folders.dashboards.space.id dashboards.space.id = folders.dashboards.space.parent_id dashboards.space.parent_id = folders.dashboards.space.parent_id dashboards.space.id = folders.looks.space.id dashboards.space.parent_id = folders.looks.space.id dashboards.space.id = folders.looks.space.parent_id dashboards.space.parent_id = folders.looks.space.parent_id dashboards.space.id = folders.looks.space_id dashboards.space.parent_id = folders.looks.space_id dashboards.space.creator_id = folders.creator_id dashboards.user_id = folders.creator_id dashboards.space.creator_id = folders.dashboards.user_id dashboards.user_id = folders.dashboards.user_id dashboards.space.creator_id = folders.dashboards.folder.creator_id dashboards.user_id = folders.dashboards.folder.creator_id dashboards.space.creator_id = folders.dashboards.space.creator_id dashboards.user_id = folders.dashboards.space.creator_id dashboards.space.creator_id = folders.looks.deleter_id dashboards.user_id = folders.looks.deleter_id dashboards.space.creator_id = folders.looks.last_updater_id dashboards.user_id = folders.looks.last_updater_id dashboards.space.creator_id = folders.looks.user.id dashboards.user_id = folders.looks.user.id |
| lookml_dashboards |
dashboards.content_favorite_id = lookml_dashboards.content_favorite_id dashboards.content_metadata_id = lookml_dashboards.content_metadata_id dashboards.folder.content_metadata_id = lookml_dashboards.content_metadata_id dashboards.space.content_metadata_id = lookml_dashboards.content_metadata_id dashboards.content_metadata_id = lookml_dashboards.folder.content_metadata_id dashboards.folder.content_metadata_id = lookml_dashboards.folder.content_metadata_id dashboards.space.content_metadata_id = lookml_dashboards.folder.content_metadata_id dashboards.content_metadata_id = lookml_dashboards.space.content_metadata_id dashboards.folder.content_metadata_id = lookml_dashboards.space.content_metadata_id dashboards.space.content_metadata_id = lookml_dashboards.space.content_metadata_id dashboards.folder.id = lookml_dashboards.folder.id dashboards.folder.parent_id = lookml_dashboards.folder.id dashboards.folder.id = lookml_dashboards.folder.parent_id dashboards.folder.parent_id = lookml_dashboards.folder.parent_id dashboards.model.id = lookml_dashboards.model.id dashboards.space.id = lookml_dashboards.space.id dashboards.space.parent_id = lookml_dashboards.space.id dashboards.space.id = lookml_dashboards.space.parent_id dashboards.space.parent_id = lookml_dashboards.space.parent_id dashboards.space.creator_id = lookml_dashboards.folder.creator_id dashboards.user_id = lookml_dashboards.folder.creator_id dashboards.space.creator_id = lookml_dashboards.space.creator_id dashboards.user_id = lookml_dashboards.space.creator_id dashboards.space.creator_id = lookml_dashboards.user_id dashboards.user_id = lookml_dashboards.user_id |
| looks |
dashboards.content_favorite_id = looks.content_favorite_id dashboards.content_metadata_id = looks.content_metadata_id dashboards.folder.content_metadata_id = looks.content_metadata_id dashboards.space.content_metadata_id = looks.content_metadata_id dashboards.folder.id = looks.folder.id dashboards.folder.parent_id = looks.folder.id dashboards.folder.id = looks.folder_id dashboards.folder.parent_id = looks.folder_id dashboards.folder.id = looks.folder.parent_id dashboards.folder.parent_id = looks.folder.parent_id dashboards.model.id = looks.model.id dashboards.space.id = looks.space.id dashboards.space.parent_id = looks.space.id dashboards.space.id = looks.space.parent_id dashboards.space.parent_id = looks.space.parent_id dashboards.space.id = looks.space_id dashboards.space.parent_id = looks.space_id dashboards.space.creator_id = looks.deleter_id dashboards.user_id = looks.deleter_id dashboards.space.creator_id = looks.folder.creator_id dashboards.user_id = looks.folder.creator_id dashboards.space.creator_id = looks.user.id dashboards.user_id = looks.user.id dashboards.space.creator_id = looks.user_id dashboards.user_id = looks.user_id |
| content_metadata |
dashboards.content_metadata_id = content_metadata.id dashboards.folder.content_metadata_id = content_metadata.id dashboards.space.content_metadata_id = content_metadata.id dashboards.content_metadata_id = content_metadata.parent_id dashboards.folder.content_metadata_id = content_metadata.parent_id dashboards.space.content_metadata_id = content_metadata.parent_id dashboards.id = content_metadata.dashboard_id dashboards.space.id = content_metadata.space_id dashboards.space.parent_id = content_metadata.space_id |
| content_metadata_access |
dashboards.content_metadata_id = content_metadata_access.content_metadata_id dashboards.folder.content_metadata_id = content_metadata_access.content_metadata_id dashboards.space.content_metadata_id = content_metadata_access.content_metadata_id |
| content_views |
dashboards.content_metadata_id = content_views.content_metadata_id dashboards.folder.content_metadata_id = content_views.content_metadata_id dashboards.space.content_metadata_id = content_views.content_metadata_id dashboards.id = content_views.dashboard_id dashboards.space.creator_id = content_views.user_id dashboards.user_id = content_views.user_id |
| dashboard_filters |
dashboards.id = dashboard_filters.dashboard_id |
| dashboard_layouts |
dashboards.id = dashboard_layouts.dashboard_id |
| scheduled_plans |
dashboards.id = scheduled_plans.dashboard_id dashboards.space.creator_id = scheduled_plans.user.id dashboards.user_id = scheduled_plans.user.id dashboards.space.creator_id = scheduled_plans.user_id dashboards.user_id = scheduled_plans.user_id |
| users |
dashboards.folder.id = users.home_folder_id dashboards.folder.parent_id = users.home_folder_id dashboards.folder.id = users.personal_folder_id dashboards.folder.parent_id = users.personal_folder_id dashboards.space.id = users.home_space_id dashboards.space.parent_id = users.home_space_id dashboards.space.id = users.personal_space_id dashboards.space.parent_id = users.personal_space_id dashboards.space.creator_id = users.id dashboards.user_id = users.id |
| roles |
dashboards.model.id = roles.model_set.models |
| connections |
dashboards.space.creator_id = connections.user_id dashboards.user_id = connections.user_id |
| user_login_lockouts |
dashboards.space.creator_id = user_login_lockouts.user_id dashboards.user_id = user_login_lockouts.user_id |
|
content_favorite_id STRING |
||||||||||||||
|
content_metadata_id STRING |
||||||||||||||
|
description STRING |
||||||||||||||
|
folder OBJECT
|
||||||||||||||
|
hidden BOOLEAN |
||||||||||||||
|
id
STRING |
||||||||||||||
|
model OBJECT
|
||||||||||||||
|
query_timezone STRING |
||||||||||||||
|
readonly BOOLEAN |
||||||||||||||
|
refresh_interval STRING |
||||||||||||||
|
refresh_interval_to_i INTEGER |
||||||||||||||
|
space OBJECT
|
||||||||||||||
|
title STRING |
||||||||||||||
|
user_id STRING |
datagroups
The datagroups table contains information about all datagroups in your Looker instance.
|
Full Table |
|
|
Primary Key |
id |
| Useful links |
|
created_at INTEGER |
|
id
STRING |
|
model_name STRING |
|
name STRING |
|
stale_before INTEGER |
|
trigger_check_at INTEGER |
|
trigger_error STRING |
|
trigger_value STRING |
|
triggered_at INTEGER |
explores
The explores table contains information about LookML model explores in your Looker instance.
|
Full Table |
|
|
Primary Key |
id |
| Useful links |
|
access_filter_fields ARRAY |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
access_filters ARRAY
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
aliases ARRAY
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
always_filter ARRAY
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
can_explain BOOLEAN |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
can_pivot_in_db BOOLEAN |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
can_save BOOLEAN |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
can_subtotal BOOLEAN |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
can_total BOOLEAN |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
conditionally_filter ARRAY
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
connection_name STRING |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
description STRING |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
errors ARRAY
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
fields OBJECT
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
files ARRAY |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
group_label STRING |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
has_timezone_support BOOLEAN |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
hidden BOOLEAN |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
id
STRING |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
index_fields ARRAY |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
joins ARRAY
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
label STRING |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
model_name STRING |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
name STRING |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
null_sort_treatment STRING |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
project_name STRING |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
scopes ARRAY |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
sets ARRAY
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
source_file STRING |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
sql_table_name STRING |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
supported_measure_types ARRAY
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
supports_cost_estimate BOOLEAN |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
tags ARRAY |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
view_name STRING |
folders
The folders table contains information about all folders in your Looker instance.
|
Full Table |
|
|
Primary Key |
id |
| Useful links |
| Join folders with | on |
|---|---|
| content_favorites |
folders.dashboards.content_favorite_id = content_favorites.id folders.looks.content_favorite_id = content_favorites.id folders.dashboards.content_favorite_id = content_favorites.dashboard.content_favorite_id folders.looks.content_favorite_id = content_favorites.dashboard.content_favorite_id folders.dashboards.folder.content_metadata_id = content_favorites.content_metadata_id folders.dashboards.space.content_metadata_id = content_favorites.content_metadata_id folders.looks.content_metadata_id = content_favorites.content_metadata_id folders.looks.folder.content_metadata_id = content_favorites.content_metadata_id folders.dashboards.folder.content_metadata_id = content_favorites.dashboard.content_metadata_id folders.dashboards.space.content_metadata_id = content_favorites.dashboard.content_metadata_id folders.looks.content_metadata_id = content_favorites.dashboard.content_metadata_id folders.looks.folder.content_metadata_id = content_favorites.dashboard.content_metadata_id folders.dashboards.folder.content_metadata_id = content_favorites.dashboard.folder.content_metadata_id folders.dashboards.space.content_metadata_id = content_favorites.dashboard.folder.content_metadata_id folders.looks.content_metadata_id = content_favorites.dashboard.folder.content_metadata_id folders.looks.folder.content_metadata_id = content_favorites.dashboard.folder.content_metadata_id folders.dashboards.folder.content_metadata_id = content_favorites.dashboard.space.content_metadata_id folders.dashboards.space.content_metadata_id = content_favorites.dashboard.space.content_metadata_id folders.looks.content_metadata_id = content_favorites.dashboard.space.content_metadata_id folders.looks.folder.content_metadata_id = content_favorites.dashboard.space.content_metadata_id folders.dashboards.folder.content_metadata_id = content_favorites.look.content_metadata_id folders.dashboards.space.content_metadata_id = content_favorites.look.content_metadata_id folders.looks.content_metadata_id = content_favorites.look.content_metadata_id folders.looks.folder.content_metadata_id = content_favorites.look.content_metadata_id folders.dashboards.id = content_favorites.dashboard.id folders.dashboards.id = content_favorites.dashboard_id folders.id = content_favorites.dashboard.folder.id folders.dashboards.folder.id = content_favorites.dashboard.folder.id folders.dashboards.folder.parent_id = content_favorites.dashboard.folder.id folders.looks.folder.id = content_favorites.dashboard.folder.id folders.looks.folder.parent_id = content_favorites.dashboard.folder.id folders.parent_id = content_favorites.dashboard.folder.id folders.id = content_favorites.dashboard.folder.parent_id folders.dashboards.folder.id = content_favorites.dashboard.folder.parent_id folders.dashboards.folder.parent_id = content_favorites.dashboard.folder.parent_id folders.looks.folder.id = content_favorites.dashboard.folder.parent_id folders.looks.folder.parent_id = content_favorites.dashboard.folder.parent_id folders.parent_id = content_favorites.dashboard.folder.parent_id folders.looks.id = content_favorites.look_id folders.looks.id = content_favorites.look.id folders.dashboards.model.id = content_favorites.dashboard.model.id folders.looks.model.id = content_favorites.dashboard.model.id folders.dashboards.space.id = content_favorites.dashboard.space.id folders.dashboards.space.parent_id = content_favorites.dashboard.space.id folders.looks.space.id = content_favorites.dashboard.space.id folders.looks.space.parent_id = content_favorites.dashboard.space.id folders.looks.space_id = content_favorites.dashboard.space.id folders.dashboards.space.id = content_favorites.dashboard.space.parent_id folders.dashboards.space.parent_id = content_favorites.dashboard.space.parent_id folders.looks.space.id = content_favorites.dashboard.space.parent_id folders.looks.space.parent_id = content_favorites.dashboard.space.parent_id folders.looks.space_id = content_favorites.dashboard.space.parent_id folders.creator_id = content_favorites.dashboard.folder.creator_id folders.dashboards.user_id = content_favorites.dashboard.folder.creator_id folders.dashboards.folder.creator_id = content_favorites.dashboard.folder.creator_id folders.dashboards.space.creator_id = content_favorites.dashboard.folder.creator_id folders.looks.deleter_id = content_favorites.dashboard.folder.creator_id folders.looks.last_updater_id = content_favorites.dashboard.folder.creator_id folders.looks.user.id = content_favorites.dashboard.folder.creator_id folders.creator_id = content_favorites.dashboard.space.creator_id folders.dashboards.user_id = content_favorites.dashboard.space.creator_id folders.dashboards.folder.creator_id = content_favorites.dashboard.space.creator_id folders.dashboards.space.creator_id = content_favorites.dashboard.space.creator_id folders.looks.deleter_id = content_favorites.dashboard.space.creator_id folders.looks.last_updater_id = content_favorites.dashboard.space.creator_id folders.looks.user.id = content_favorites.dashboard.space.creator_id folders.creator_id = content_favorites.user_id folders.dashboards.user_id = content_favorites.user_id folders.dashboards.folder.creator_id = content_favorites.user_id folders.dashboards.space.creator_id = content_favorites.user_id folders.looks.deleter_id = content_favorites.user_id folders.looks.last_updater_id = content_favorites.user_id folders.looks.user.id = content_favorites.user_id |
| dashboard_elements |
folders.dashboards.content_favorite_id = dashboard_elements.look.content_favorite_id folders.looks.content_favorite_id = dashboard_elements.look.content_favorite_id folders.dashboards.folder.content_metadata_id = dashboard_elements.look.content_metadata_id folders.dashboards.space.content_metadata_id = dashboard_elements.look.content_metadata_id folders.looks.content_metadata_id = dashboard_elements.look.content_metadata_id folders.looks.folder.content_metadata_id = dashboard_elements.look.content_metadata_id folders.dashboards.folder.content_metadata_id = dashboard_elements.look.folder.content_metadata_id folders.dashboards.space.content_metadata_id = dashboard_elements.look.folder.content_metadata_id folders.looks.content_metadata_id = dashboard_elements.look.folder.content_metadata_id folders.looks.folder.content_metadata_id = dashboard_elements.look.folder.content_metadata_id folders.dashboards.folder.content_metadata_id = dashboard_elements.look.space.content_metadata_id folders.dashboards.space.content_metadata_id = dashboard_elements.look.space.content_metadata_id folders.looks.content_metadata_id = dashboard_elements.look.space.content_metadata_id folders.looks.folder.content_metadata_id = dashboard_elements.look.space.content_metadata_id folders.dashboards.id = dashboard_elements.dashboard_id folders.id = dashboard_elements.look.folder.id folders.dashboards.folder.id = dashboard_elements.look.folder.id folders.dashboards.folder.parent_id = dashboard_elements.look.folder.id folders.looks.folder.id = dashboard_elements.look.folder.id folders.looks.folder.parent_id = dashboard_elements.look.folder.id folders.parent_id = dashboard_elements.look.folder.id folders.id = dashboard_elements.look.folder.parent_id folders.dashboards.folder.id = dashboard_elements.look.folder.parent_id folders.dashboards.folder.parent_id = dashboard_elements.look.folder.parent_id folders.looks.folder.id = dashboard_elements.look.folder.parent_id folders.looks.folder.parent_id = dashboard_elements.look.folder.parent_id folders.parent_id = dashboard_elements.look.folder.parent_id folders.id = dashboard_elements.look.folder_id folders.dashboards.folder.id = dashboard_elements.look.folder_id folders.dashboards.folder.parent_id = dashboard_elements.look.folder_id folders.looks.folder.id = dashboard_elements.look.folder_id folders.looks.folder.parent_id = dashboard_elements.look.folder_id folders.parent_id = dashboard_elements.look.folder_id folders.looks.id = dashboard_elements.look.id folders.looks.id = dashboard_elements.look_id folders.dashboards.model.id = dashboard_elements.look.model.id folders.looks.model.id = dashboard_elements.look.model.id folders.looks.query_id = dashboard_elements.look.query.id folders.looks.query_id = dashboard_elements.look.query_id folders.looks.query_id = dashboard_elements.query.id folders.looks.query_id = dashboard_elements.query_id folders.looks.query_id = dashboard_elements.result_maker.query.id folders.looks.query_id = dashboard_elements.result_maker.query_id folders.dashboards.space.id = dashboard_elements.look.space.id folders.dashboards.space.parent_id = dashboard_elements.look.space.id folders.looks.space.id = dashboard_elements.look.space.id folders.looks.space.parent_id = dashboard_elements.look.space.id folders.looks.space_id = dashboard_elements.look.space.id folders.dashboards.space.id = dashboard_elements.look.space.parent_id folders.dashboards.space.parent_id = dashboard_elements.look.space.parent_id folders.looks.space.id = dashboard_elements.look.space.parent_id folders.looks.space.parent_id = dashboard_elements.look.space.parent_id folders.looks.space_id = dashboard_elements.look.space.parent_id folders.creator_id = dashboard_elements.look.deleter_id folders.dashboards.user_id = dashboard_elements.look.deleter_id folders.dashboards.folder.creator_id = dashboard_elements.look.deleter_id folders.dashboards.space.creator_id = dashboard_elements.look.deleter_id folders.looks.deleter_id = dashboard_elements.look.deleter_id folders.looks.last_updater_id = dashboard_elements.look.deleter_id folders.looks.user.id = dashboard_elements.look.deleter_id folders.creator_id = dashboard_elements.look.folder.creator_id folders.dashboards.user_id = dashboard_elements.look.folder.creator_id folders.dashboards.folder.creator_id = dashboard_elements.look.folder.creator_id folders.dashboards.space.creator_id = dashboard_elements.look.folder.creator_id folders.looks.deleter_id = dashboard_elements.look.folder.creator_id folders.looks.last_updater_id = dashboard_elements.look.folder.creator_id folders.looks.user.id = dashboard_elements.look.folder.creator_id folders.creator_id = dashboard_elements.look.last_updater_id folders.dashboards.user_id = dashboard_elements.look.last_updater_id folders.dashboards.folder.creator_id = dashboard_elements.look.last_updater_id folders.dashboards.space.creator_id = dashboard_elements.look.last_updater_id folders.looks.deleter_id = dashboard_elements.look.last_updater_id folders.looks.last_updater_id = dashboard_elements.look.last_updater_id folders.looks.user.id = dashboard_elements.look.last_updater_id folders.creator_id = dashboard_elements.look.space.creator_id folders.dashboards.user_id = dashboard_elements.look.space.creator_id folders.dashboards.folder.creator_id = dashboard_elements.look.space.creator_id folders.dashboards.space.creator_id = dashboard_elements.look.space.creator_id folders.looks.deleter_id = dashboard_elements.look.space.creator_id folders.looks.last_updater_id = dashboard_elements.look.space.creator_id folders.looks.user.id = dashboard_elements.look.space.creator_id folders.creator_id = dashboard_elements.look.user.id folders.dashboards.user_id = dashboard_elements.look.user.id folders.dashboards.folder.creator_id = dashboard_elements.look.user.id folders.dashboards.space.creator_id = dashboard_elements.look.user.id folders.looks.deleter_id = dashboard_elements.look.user.id folders.looks.last_updater_id = dashboard_elements.look.user.id folders.looks.user.id = dashboard_elements.look.user.id folders.creator_id = dashboard_elements.look.user_id folders.dashboards.user_id = dashboard_elements.look.user_id folders.dashboards.folder.creator_id = dashboard_elements.look.user_id folders.dashboards.space.creator_id = dashboard_elements.look.user_id folders.looks.deleter_id = dashboard_elements.look.user_id folders.looks.last_updater_id = dashboard_elements.look.user_id folders.looks.user.id = dashboard_elements.look.user_id |
| dashboards |
folders.dashboards.content_favorite_id = dashboards.content_favorite_id folders.looks.content_favorite_id = dashboards.content_favorite_id folders.dashboards.folder.content_metadata_id = dashboards.content_metadata_id folders.dashboards.space.content_metadata_id = dashboards.content_metadata_id folders.looks.content_metadata_id = dashboards.content_metadata_id folders.looks.folder.content_metadata_id = dashboards.content_metadata_id folders.dashboards.folder.content_metadata_id = dashboards.folder.content_metadata_id folders.dashboards.space.content_metadata_id = dashboards.folder.content_metadata_id folders.looks.content_metadata_id = dashboards.folder.content_metadata_id folders.looks.folder.content_metadata_id = dashboards.folder.content_metadata_id folders.dashboards.folder.content_metadata_id = dashboards.space.content_metadata_id folders.dashboards.space.content_metadata_id = dashboards.space.content_metadata_id folders.looks.content_metadata_id = dashboards.space.content_metadata_id folders.looks.folder.content_metadata_id = dashboards.space.content_metadata_id folders.dashboards.id = dashboards.id folders.id = dashboards.folder.id folders.dashboards.folder.id = dashboards.folder.id folders.dashboards.folder.parent_id = dashboards.folder.id folders.looks.folder.id = dashboards.folder.id folders.looks.folder.parent_id = dashboards.folder.id folders.parent_id = dashboards.folder.id folders.id = dashboards.folder.parent_id folders.dashboards.folder.id = dashboards.folder.parent_id folders.dashboards.folder.parent_id = dashboards.folder.parent_id folders.looks.folder.id = dashboards.folder.parent_id folders.looks.folder.parent_id = dashboards.folder.parent_id folders.parent_id = dashboards.folder.parent_id folders.dashboards.model.id = dashboards.model.id folders.looks.model.id = dashboards.model.id folders.dashboards.space.id = dashboards.space.id folders.dashboards.space.parent_id = dashboards.space.id folders.looks.space.id = dashboards.space.id folders.looks.space.parent_id = dashboards.space.id folders.looks.space_id = dashboards.space.id folders.dashboards.space.id = dashboards.space.parent_id folders.dashboards.space.parent_id = dashboards.space.parent_id folders.looks.space.id = dashboards.space.parent_id folders.looks.space.parent_id = dashboards.space.parent_id folders.looks.space_id = dashboards.space.parent_id folders.creator_id = dashboards.space.creator_id folders.dashboards.user_id = dashboards.space.creator_id folders.dashboards.folder.creator_id = dashboards.space.creator_id folders.dashboards.space.creator_id = dashboards.space.creator_id folders.looks.deleter_id = dashboards.space.creator_id folders.looks.last_updater_id = dashboards.space.creator_id folders.looks.user.id = dashboards.space.creator_id folders.creator_id = dashboards.user_id folders.dashboards.user_id = dashboards.user_id folders.dashboards.folder.creator_id = dashboards.user_id folders.dashboards.space.creator_id = dashboards.user_id folders.looks.deleter_id = dashboards.user_id folders.looks.last_updater_id = dashboards.user_id folders.looks.user.id = dashboards.user_id |
| lookml_dashboards |
folders.dashboards.content_favorite_id = lookml_dashboards.content_favorite_id folders.looks.content_favorite_id = lookml_dashboards.content_favorite_id folders.dashboards.folder.content_metadata_id = lookml_dashboards.content_metadata_id folders.dashboards.space.content_metadata_id = lookml_dashboards.content_metadata_id folders.looks.content_metadata_id = lookml_dashboards.content_metadata_id folders.looks.folder.content_metadata_id = lookml_dashboards.content_metadata_id folders.dashboards.folder.content_metadata_id = lookml_dashboards.folder.content_metadata_id folders.dashboards.space.content_metadata_id = lookml_dashboards.folder.content_metadata_id folders.looks.content_metadata_id = lookml_dashboards.folder.content_metadata_id folders.looks.folder.content_metadata_id = lookml_dashboards.folder.content_metadata_id folders.dashboards.folder.content_metadata_id = lookml_dashboards.space.content_metadata_id folders.dashboards.space.content_metadata_id = lookml_dashboards.space.content_metadata_id folders.looks.content_metadata_id = lookml_dashboards.space.content_metadata_id folders.looks.folder.content_metadata_id = lookml_dashboards.space.content_metadata_id folders.id = lookml_dashboards.folder.id folders.dashboards.folder.id = lookml_dashboards.folder.id folders.dashboards.folder.parent_id = lookml_dashboards.folder.id folders.looks.folder.id = lookml_dashboards.folder.id folders.looks.folder.parent_id = lookml_dashboards.folder.id folders.parent_id = lookml_dashboards.folder.id folders.id = lookml_dashboards.folder.parent_id folders.dashboards.folder.id = lookml_dashboards.folder.parent_id folders.dashboards.folder.parent_id = lookml_dashboards.folder.parent_id folders.looks.folder.id = lookml_dashboards.folder.parent_id folders.looks.folder.parent_id = lookml_dashboards.folder.parent_id folders.parent_id = lookml_dashboards.folder.parent_id folders.dashboards.model.id = lookml_dashboards.model.id folders.looks.model.id = lookml_dashboards.model.id folders.dashboards.space.id = lookml_dashboards.space.id folders.dashboards.space.parent_id = lookml_dashboards.space.id folders.looks.space.id = lookml_dashboards.space.id folders.looks.space.parent_id = lookml_dashboards.space.id folders.looks.space_id = lookml_dashboards.space.id folders.dashboards.space.id = lookml_dashboards.space.parent_id folders.dashboards.space.parent_id = lookml_dashboards.space.parent_id folders.looks.space.id = lookml_dashboards.space.parent_id folders.looks.space.parent_id = lookml_dashboards.space.parent_id folders.looks.space_id = lookml_dashboards.space.parent_id folders.creator_id = lookml_dashboards.folder.creator_id folders.dashboards.user_id = lookml_dashboards.folder.creator_id folders.dashboards.folder.creator_id = lookml_dashboards.folder.creator_id folders.dashboards.space.creator_id = lookml_dashboards.folder.creator_id folders.looks.deleter_id = lookml_dashboards.folder.creator_id folders.looks.last_updater_id = lookml_dashboards.folder.creator_id folders.looks.user.id = lookml_dashboards.folder.creator_id folders.creator_id = lookml_dashboards.space.creator_id folders.dashboards.user_id = lookml_dashboards.space.creator_id folders.dashboards.folder.creator_id = lookml_dashboards.space.creator_id folders.dashboards.space.creator_id = lookml_dashboards.space.creator_id folders.looks.deleter_id = lookml_dashboards.space.creator_id folders.looks.last_updater_id = lookml_dashboards.space.creator_id folders.looks.user.id = lookml_dashboards.space.creator_id folders.creator_id = lookml_dashboards.user_id folders.dashboards.user_id = lookml_dashboards.user_id folders.dashboards.folder.creator_id = lookml_dashboards.user_id folders.dashboards.space.creator_id = lookml_dashboards.user_id folders.looks.deleter_id = lookml_dashboards.user_id folders.looks.last_updater_id = lookml_dashboards.user_id folders.looks.user.id = lookml_dashboards.user_id |
| looks |
folders.dashboards.content_favorite_id = looks.content_favorite_id folders.looks.content_favorite_id = looks.content_favorite_id folders.dashboards.folder.content_metadata_id = looks.content_metadata_id folders.dashboards.space.content_metadata_id = looks.content_metadata_id folders.looks.content_metadata_id = looks.content_metadata_id folders.looks.folder.content_metadata_id = looks.content_metadata_id folders.id = looks.folder.id folders.dashboards.folder.id = looks.folder.id folders.dashboards.folder.parent_id = looks.folder.id folders.looks.folder.id = looks.folder.id folders.looks.folder.parent_id = looks.folder.id folders.parent_id = looks.folder.id folders.id = looks.folder_id folders.dashboards.folder.id = looks.folder_id folders.dashboards.folder.parent_id = looks.folder_id folders.looks.folder.id = looks.folder_id folders.looks.folder.parent_id = looks.folder_id folders.parent_id = looks.folder_id folders.id = looks.folder.parent_id folders.dashboards.folder.id = looks.folder.parent_id folders.dashboards.folder.parent_id = looks.folder.parent_id folders.looks.folder.id = looks.folder.parent_id folders.looks.folder.parent_id = looks.folder.parent_id folders.parent_id = looks.folder.parent_id folders.looks.id = looks.id folders.dashboards.model.id = looks.model.id folders.looks.model.id = looks.model.id folders.looks.query_id = looks.query_id folders.dashboards.space.id = looks.space.id folders.dashboards.space.parent_id = looks.space.id folders.looks.space.id = looks.space.id folders.looks.space.parent_id = looks.space.id folders.looks.space_id = looks.space.id folders.dashboards.space.id = looks.space.parent_id folders.dashboards.space.parent_id = looks.space.parent_id folders.looks.space.id = looks.space.parent_id folders.looks.space.parent_id = looks.space.parent_id folders.looks.space_id = looks.space.parent_id folders.dashboards.space.id = looks.space_id folders.dashboards.space.parent_id = looks.space_id folders.looks.space.id = looks.space_id folders.looks.space.parent_id = looks.space_id folders.looks.space_id = looks.space_id folders.creator_id = looks.deleter_id folders.dashboards.user_id = looks.deleter_id folders.dashboards.folder.creator_id = looks.deleter_id folders.dashboards.space.creator_id = looks.deleter_id folders.looks.deleter_id = looks.deleter_id folders.looks.last_updater_id = looks.deleter_id folders.looks.user.id = looks.deleter_id folders.creator_id = looks.folder.creator_id folders.dashboards.user_id = looks.folder.creator_id folders.dashboards.folder.creator_id = looks.folder.creator_id folders.dashboards.space.creator_id = looks.folder.creator_id folders.looks.deleter_id = looks.folder.creator_id folders.looks.last_updater_id = looks.folder.creator_id folders.looks.user.id = looks.folder.creator_id folders.creator_id = looks.user.id folders.dashboards.user_id = looks.user.id folders.dashboards.folder.creator_id = looks.user.id folders.dashboards.space.creator_id = looks.user.id folders.looks.deleter_id = looks.user.id folders.looks.last_updater_id = looks.user.id folders.looks.user.id = looks.user.id folders.creator_id = looks.user_id folders.dashboards.user_id = looks.user_id folders.dashboards.folder.creator_id = looks.user_id folders.dashboards.space.creator_id = looks.user_id folders.looks.deleter_id = looks.user_id folders.looks.last_updater_id = looks.user_id folders.looks.user.id = looks.user_id |
| content_metadata |
folders.dashboards.folder.content_metadata_id = content_metadata.id folders.dashboards.space.content_metadata_id = content_metadata.id folders.looks.content_metadata_id = content_metadata.id folders.looks.folder.content_metadata_id = content_metadata.id folders.dashboards.folder.content_metadata_id = content_metadata.parent_id folders.dashboards.space.content_metadata_id = content_metadata.parent_id folders.looks.content_metadata_id = content_metadata.parent_id folders.looks.folder.content_metadata_id = content_metadata.parent_id folders.dashboards.id = content_metadata.dashboard_id folders.looks.id = content_metadata.look_id folders.dashboards.space.id = content_metadata.space_id folders.dashboards.space.parent_id = content_metadata.space_id folders.looks.space.id = content_metadata.space_id folders.looks.space.parent_id = content_metadata.space_id folders.looks.space_id = content_metadata.space_id |
| content_metadata_access |
folders.dashboards.folder.content_metadata_id = content_metadata_access.content_metadata_id folders.dashboards.space.content_metadata_id = content_metadata_access.content_metadata_id folders.looks.content_metadata_id = content_metadata_access.content_metadata_id folders.looks.folder.content_metadata_id = content_metadata_access.content_metadata_id |
| content_views |
folders.dashboards.folder.content_metadata_id = content_views.content_metadata_id folders.dashboards.space.content_metadata_id = content_views.content_metadata_id folders.looks.content_metadata_id = content_views.content_metadata_id folders.looks.folder.content_metadata_id = content_views.content_metadata_id folders.dashboards.id = content_views.dashboard_id folders.looks.id = content_views.look_id folders.creator_id = content_views.user_id folders.dashboards.user_id = content_views.user_id folders.dashboards.folder.creator_id = content_views.user_id folders.dashboards.space.creator_id = content_views.user_id folders.looks.deleter_id = content_views.user_id folders.looks.last_updater_id = content_views.user_id folders.looks.user.id = content_views.user_id |
| dashboard_filters |
folders.dashboards.id = dashboard_filters.dashboard_id |
| dashboard_layouts |
folders.dashboards.id = dashboard_layouts.dashboard_id |
| scheduled_plans |
folders.dashboards.id = scheduled_plans.dashboard_id folders.looks.id = scheduled_plans.look_id folders.looks.query_id = scheduled_plans.query_id folders.creator_id = scheduled_plans.user.id folders.dashboards.user_id = scheduled_plans.user.id folders.dashboards.folder.creator_id = scheduled_plans.user.id folders.dashboards.space.creator_id = scheduled_plans.user.id folders.looks.deleter_id = scheduled_plans.user.id folders.looks.last_updater_id = scheduled_plans.user.id folders.looks.user.id = scheduled_plans.user.id folders.creator_id = scheduled_plans.user_id folders.dashboards.user_id = scheduled_plans.user_id folders.dashboards.folder.creator_id = scheduled_plans.user_id folders.dashboards.space.creator_id = scheduled_plans.user_id folders.looks.deleter_id = scheduled_plans.user_id folders.looks.last_updater_id = scheduled_plans.user_id folders.looks.user.id = scheduled_plans.user_id |
| users |
folders.id = users.home_folder_id folders.dashboards.folder.id = users.home_folder_id folders.dashboards.folder.parent_id = users.home_folder_id folders.looks.folder.id = users.home_folder_id folders.looks.folder.parent_id = users.home_folder_id folders.parent_id = users.home_folder_id folders.id = users.personal_folder_id folders.dashboards.folder.id = users.personal_folder_id folders.dashboards.folder.parent_id = users.personal_folder_id folders.looks.folder.id = users.personal_folder_id folders.looks.folder.parent_id = users.personal_folder_id folders.parent_id = users.personal_folder_id folders.dashboards.space.id = users.home_space_id folders.dashboards.space.parent_id = users.home_space_id folders.looks.space.id = users.home_space_id folders.looks.space.parent_id = users.home_space_id folders.looks.space_id = users.home_space_id folders.dashboards.space.id = users.personal_space_id folders.dashboards.space.parent_id = users.personal_space_id folders.looks.space.id = users.personal_space_id folders.looks.space.parent_id = users.personal_space_id folders.looks.space_id = users.personal_space_id folders.creator_id = users.id folders.dashboards.user_id = users.id folders.dashboards.folder.creator_id = users.id folders.dashboards.space.creator_id = users.id folders.looks.deleter_id = users.id folders.looks.last_updater_id = users.id folders.looks.user.id = users.id |
| roles |
folders.dashboards.model.id = roles.model_set.models folders.looks.model.id = roles.model_set.models |
| queries |
folders.looks.query_id = queries.id |
| connections |
folders.creator_id = connections.user_id folders.dashboards.user_id = connections.user_id folders.dashboards.folder.creator_id = connections.user_id folders.dashboards.space.creator_id = connections.user_id folders.looks.deleter_id = connections.user_id folders.looks.last_updater_id = connections.user_id folders.looks.user.id = connections.user_id |
| user_login_lockouts |
folders.creator_id = user_login_lockouts.user_id folders.dashboards.user_id = user_login_lockouts.user_id folders.dashboards.folder.creator_id = user_login_lockouts.user_id folders.dashboards.space.creator_id = user_login_lockouts.user_id folders.looks.deleter_id = user_login_lockouts.user_id folders.looks.last_updater_id = user_login_lockouts.user_id folders.looks.user.id = user_login_lockouts.user_id |
|
child_count INTEGER |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
content_metadata_id STRING |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
creator_id STRING |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
dashboards ARRAY
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
external_id STRING |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
id
STRING |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
is_embed BOOLEAN |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
is_embed_shared_root BOOLEAN |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
is_embed_users_root BOOLEAN |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
is_personal BOOLEAN |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
is_personal_descendant BOOLEAN |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
is_shared_root BOOLEAN |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
is_users_root BOOLEAN |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
looks ARRAY
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
name STRING |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
parent_id STRING |
git_branches
The git_branches table contains info about the git branches associated with projects in your Looker instance.
|
Full Table |
|
|
Primary Keys |
name project_id |
| Useful links |
| Join git_branches with | on |
|---|---|
| project_files |
git_branches.project_id = project_files.project_id |
| projects |
git_branches.project_id = projects.id |
| workspaces |
git_branches.project_id = workspaces.projects.id |
|
ahead_count INTEGER |
|
behind_count INTEGER |
|
commit_at INTEGER |
|
error STRING |
|
is_local BOOLEAN |
|
is_production BOOLEAN |
|
is_remote BOOLEAN |
|
message STRING |
|
name
STRING |
|
owner_name STRING |
|
personal BOOLEAN |
|
project_id
STRING |
|
readonly BOOLEAN |
|
ref STRING |
|
remote STRING |
|
remote_name STRING |
|
remote_ref STRING |
groups
The groups table contains information about all groups in your Looker instance.
|
Full Table |
|
|
Primary Key |
id |
| Useful links |
| Join groups with | on |
|---|---|
| content_metadata_access |
groups.id = content_metadata_access.group_id |
| content_views |
groups.id = content_views.group_id |
| groups_in_group |
groups.id = groups_in_group.id groups.id = groups_in_group.parent_group_id |
| user_attribute_group_values |
groups.id = user_attribute_group_values.group_id |
| users |
groups.id = users.group_ids |
|
can_add_to_content_metadata BOOLEAN |
|
contains_current_user BOOLEAN |
|
external_group_id STRING |
|
externally_managed BOOLEAN |
|
id
STRING |
|
include_by_default BOOLEAN |
|
name STRING |
|
user_count INTEGER |
groups_in_group
The groups_in_group table contains info about the groups contained within groups in your Looker instance.
|
Full Table |
|
|
Primary Key |
id |
| Useful links |
| Join groups_in_group with | on |
|---|---|
| content_metadata_access |
groups_in_group.id = content_metadata_access.group_id groups_in_group.parent_group_id = content_metadata_access.group_id |
| content_views |
groups_in_group.id = content_views.group_id groups_in_group.parent_group_id = content_views.group_id |
| groups |
groups_in_group.id = groups.id groups_in_group.parent_group_id = groups.id |
| user_attribute_group_values |
groups_in_group.id = user_attribute_group_values.group_id groups_in_group.parent_group_id = user_attribute_group_values.group_id |
| users |
groups_in_group.id = users.group_ids groups_in_group.parent_group_id = users.group_ids |
|
can_add_to_content_metadata BOOLEAN |
|
contains_current_user BOOLEAN |
|
external_group_id STRING |
|
externally_managed BOOLEAN |
|
id
STRING |
|
include_by_default BOOLEAN |
|
name STRING |
|
parent_group_id STRING |
|
user_count INTEGER |
integration_hubs
The integration_hubs table contains information about Integration Hubs in your Looker instance.
|
Full Table |
|
|
Primary Key |
id |
| Useful links |
| Join integration_hubs with | on |
|---|---|
| integrations |
integration_hubs.id = integrations.integration_hub_id |
|
authorization_token STRING |
|
fetch_error_message STRING |
|
has_authorization_token BOOLEAN |
|
id
STRING |
|
label STRING |
|
legal_agreement_required BOOLEAN |
|
legal_agreement_signed BOOLEAN |
|
legal_agreement_text STRING |
|
official BOOLEAN |
|
url STRING |
integrations
The integrations table contains information about all integrations in your Looker instance.
|
Full Table |
|
|
Primary Key |
id |
| Useful links |
| Join integrations with | on |
|---|---|
| integration_hubs |
integrations.integration_hub_id = integration_hubs.id |
|
delegate_oauth BOOLEAN |
||||||||||
|
description STRING |
||||||||||
|
enabled BOOLEAN |
||||||||||
|
icon_url STRING |
||||||||||
|
id
STRING |
||||||||||
|
installed_delegate_oauth STRING |
||||||||||
|
integration_hub_id STRING |
||||||||||
|
label STRING |
||||||||||
|
params ARRAY
|
||||||||||
|
required_fields ARRAY
|
||||||||||
|
supported_action_types ARRAY |
||||||||||
|
supported_download_settings ARRAY |
||||||||||
|
supported_formats ARRAY |
||||||||||
|
supported_formattings ARRAY |
||||||||||
|
supported_visualization_formattings ARRAY |
||||||||||
|
uses_oauth BOOLEAN |
lookml_dashboards
The lookml_dashboards table contains information about LookML dashboards in your Looker instance.
|
Full Table |
|
|
Primary Key |
id |
| Useful links |
| Join lookml_dashboards with | on |
|---|---|
| content_favorites |
lookml_dashboards.content_favorite_id = content_favorites.id lookml_dashboards.content_favorite_id = content_favorites.dashboard.content_favorite_id lookml_dashboards.content_metadata_id = content_favorites.content_metadata_id lookml_dashboards.folder.content_metadata_id = content_favorites.content_metadata_id lookml_dashboards.space.content_metadata_id = content_favorites.content_metadata_id lookml_dashboards.content_metadata_id = content_favorites.dashboard.content_metadata_id lookml_dashboards.folder.content_metadata_id = content_favorites.dashboard.content_metadata_id lookml_dashboards.space.content_metadata_id = content_favorites.dashboard.content_metadata_id lookml_dashboards.content_metadata_id = content_favorites.dashboard.folder.content_metadata_id lookml_dashboards.folder.content_metadata_id = content_favorites.dashboard.folder.content_metadata_id lookml_dashboards.space.content_metadata_id = content_favorites.dashboard.folder.content_metadata_id lookml_dashboards.content_metadata_id = content_favorites.dashboard.space.content_metadata_id lookml_dashboards.folder.content_metadata_id = content_favorites.dashboard.space.content_metadata_id lookml_dashboards.space.content_metadata_id = content_favorites.dashboard.space.content_metadata_id lookml_dashboards.content_metadata_id = content_favorites.look.content_metadata_id lookml_dashboards.folder.content_metadata_id = content_favorites.look.content_metadata_id lookml_dashboards.space.content_metadata_id = content_favorites.look.content_metadata_id lookml_dashboards.folder.id = content_favorites.dashboard.folder.id lookml_dashboards.folder.parent_id = content_favorites.dashboard.folder.id lookml_dashboards.folder.id = content_favorites.dashboard.folder.parent_id lookml_dashboards.folder.parent_id = content_favorites.dashboard.folder.parent_id lookml_dashboards.model.id = content_favorites.dashboard.model.id lookml_dashboards.space.id = content_favorites.dashboard.space.id lookml_dashboards.space.parent_id = content_favorites.dashboard.space.id lookml_dashboards.space.id = content_favorites.dashboard.space.parent_id lookml_dashboards.space.parent_id = content_favorites.dashboard.space.parent_id lookml_dashboards.folder.creator_id = content_favorites.dashboard.folder.creator_id lookml_dashboards.space.creator_id = content_favorites.dashboard.folder.creator_id lookml_dashboards.user_id = content_favorites.dashboard.folder.creator_id lookml_dashboards.folder.creator_id = content_favorites.dashboard.space.creator_id lookml_dashboards.space.creator_id = content_favorites.dashboard.space.creator_id lookml_dashboards.user_id = content_favorites.dashboard.space.creator_id lookml_dashboards.folder.creator_id = content_favorites.user_id lookml_dashboards.space.creator_id = content_favorites.user_id lookml_dashboards.user_id = content_favorites.user_id |
| dashboard_elements |
lookml_dashboards.content_favorite_id = dashboard_elements.look.content_favorite_id lookml_dashboards.content_metadata_id = dashboard_elements.look.content_metadata_id lookml_dashboards.folder.content_metadata_id = dashboard_elements.look.content_metadata_id lookml_dashboards.space.content_metadata_id = dashboard_elements.look.content_metadata_id lookml_dashboards.content_metadata_id = dashboard_elements.look.folder.content_metadata_id lookml_dashboards.folder.content_metadata_id = dashboard_elements.look.folder.content_metadata_id lookml_dashboards.space.content_metadata_id = dashboard_elements.look.folder.content_metadata_id lookml_dashboards.content_metadata_id = dashboard_elements.look.space.content_metadata_id lookml_dashboards.folder.content_metadata_id = dashboard_elements.look.space.content_metadata_id lookml_dashboards.space.content_metadata_id = dashboard_elements.look.space.content_metadata_id lookml_dashboards.folder.id = dashboard_elements.look.folder.id lookml_dashboards.folder.parent_id = dashboard_elements.look.folder.id lookml_dashboards.folder.id = dashboard_elements.look.folder.parent_id lookml_dashboards.folder.parent_id = dashboard_elements.look.folder.parent_id lookml_dashboards.folder.id = dashboard_elements.look.folder_id lookml_dashboards.folder.parent_id = dashboard_elements.look.folder_id lookml_dashboards.model.id = dashboard_elements.look.model.id lookml_dashboards.space.id = dashboard_elements.look.space.id lookml_dashboards.space.parent_id = dashboard_elements.look.space.id lookml_dashboards.space.id = dashboard_elements.look.space.parent_id lookml_dashboards.space.parent_id = dashboard_elements.look.space.parent_id lookml_dashboards.folder.creator_id = dashboard_elements.look.deleter_id lookml_dashboards.space.creator_id = dashboard_elements.look.deleter_id lookml_dashboards.user_id = dashboard_elements.look.deleter_id lookml_dashboards.folder.creator_id = dashboard_elements.look.folder.creator_id lookml_dashboards.space.creator_id = dashboard_elements.look.folder.creator_id lookml_dashboards.user_id = dashboard_elements.look.folder.creator_id lookml_dashboards.folder.creator_id = dashboard_elements.look.last_updater_id lookml_dashboards.space.creator_id = dashboard_elements.look.last_updater_id lookml_dashboards.user_id = dashboard_elements.look.last_updater_id lookml_dashboards.folder.creator_id = dashboard_elements.look.space.creator_id lookml_dashboards.space.creator_id = dashboard_elements.look.space.creator_id lookml_dashboards.user_id = dashboard_elements.look.space.creator_id lookml_dashboards.folder.creator_id = dashboard_elements.look.user.id lookml_dashboards.space.creator_id = dashboard_elements.look.user.id lookml_dashboards.user_id = dashboard_elements.look.user.id lookml_dashboards.folder.creator_id = dashboard_elements.look.user_id lookml_dashboards.space.creator_id = dashboard_elements.look.user_id lookml_dashboards.user_id = dashboard_elements.look.user_id |
| dashboards |
lookml_dashboards.content_favorite_id = dashboards.content_favorite_id lookml_dashboards.content_metadata_id = dashboards.content_metadata_id lookml_dashboards.folder.content_metadata_id = dashboards.content_metadata_id lookml_dashboards.space.content_metadata_id = dashboards.content_metadata_id lookml_dashboards.content_metadata_id = dashboards.folder.content_metadata_id lookml_dashboards.folder.content_metadata_id = dashboards.folder.content_metadata_id lookml_dashboards.space.content_metadata_id = dashboards.folder.content_metadata_id lookml_dashboards.content_metadata_id = dashboards.space.content_metadata_id lookml_dashboards.folder.content_metadata_id = dashboards.space.content_metadata_id lookml_dashboards.space.content_metadata_id = dashboards.space.content_metadata_id lookml_dashboards.folder.id = dashboards.folder.id lookml_dashboards.folder.parent_id = dashboards.folder.id lookml_dashboards.folder.id = dashboards.folder.parent_id lookml_dashboards.folder.parent_id = dashboards.folder.parent_id lookml_dashboards.model.id = dashboards.model.id lookml_dashboards.space.id = dashboards.space.id lookml_dashboards.space.parent_id = dashboards.space.id lookml_dashboards.space.id = dashboards.space.parent_id lookml_dashboards.space.parent_id = dashboards.space.parent_id lookml_dashboards.folder.creator_id = dashboards.space.creator_id lookml_dashboards.space.creator_id = dashboards.space.creator_id lookml_dashboards.user_id = dashboards.space.creator_id lookml_dashboards.folder.creator_id = dashboards.user_id lookml_dashboards.space.creator_id = dashboards.user_id lookml_dashboards.user_id = dashboards.user_id |
| folders |
lookml_dashboards.content_favorite_id = folders.dashboards.content_favorite_id lookml_dashboards.content_favorite_id = folders.looks.content_favorite_id lookml_dashboards.content_metadata_id = folders.dashboards.folder.content_metadata_id lookml_dashboards.folder.content_metadata_id = folders.dashboards.folder.content_metadata_id lookml_dashboards.space.content_metadata_id = folders.dashboards.folder.content_metadata_id lookml_dashboards.content_metadata_id = folders.dashboards.space.content_metadata_id lookml_dashboards.folder.content_metadata_id = folders.dashboards.space.content_metadata_id lookml_dashboards.space.content_metadata_id = folders.dashboards.space.content_metadata_id lookml_dashboards.content_metadata_id = folders.looks.content_metadata_id lookml_dashboards.folder.content_metadata_id = folders.looks.content_metadata_id lookml_dashboards.space.content_metadata_id = folders.looks.content_metadata_id lookml_dashboards.content_metadata_id = folders.looks.folder.content_metadata_id lookml_dashboards.folder.content_metadata_id = folders.looks.folder.content_metadata_id lookml_dashboards.space.content_metadata_id = folders.looks.folder.content_metadata_id lookml_dashboards.folder.id = folders.id lookml_dashboards.folder.parent_id = folders.id lookml_dashboards.folder.id = folders.dashboards.folder.id lookml_dashboards.folder.parent_id = folders.dashboards.folder.id lookml_dashboards.folder.id = folders.dashboards.folder.parent_id lookml_dashboards.folder.parent_id = folders.dashboards.folder.parent_id lookml_dashboards.folder.id = folders.looks.folder.id lookml_dashboards.folder.parent_id = folders.looks.folder.id lookml_dashboards.folder.id = folders.looks.folder.parent_id lookml_dashboards.folder.parent_id = folders.looks.folder.parent_id lookml_dashboards.folder.id = folders.parent_id lookml_dashboards.folder.parent_id = folders.parent_id lookml_dashboards.model.id = folders.dashboards.model.id lookml_dashboards.model.id = folders.looks.model.id lookml_dashboards.space.id = folders.dashboards.space.id lookml_dashboards.space.parent_id = folders.dashboards.space.id lookml_dashboards.space.id = folders.dashboards.space.parent_id lookml_dashboards.space.parent_id = folders.dashboards.space.parent_id lookml_dashboards.space.id = folders.looks.space.id lookml_dashboards.space.parent_id = folders.looks.space.id lookml_dashboards.space.id = folders.looks.space.parent_id lookml_dashboards.space.parent_id = folders.looks.space.parent_id lookml_dashboards.space.id = folders.looks.space_id lookml_dashboards.space.parent_id = folders.looks.space_id lookml_dashboards.folder.creator_id = folders.creator_id lookml_dashboards.space.creator_id = folders.creator_id lookml_dashboards.user_id = folders.creator_id lookml_dashboards.folder.creator_id = folders.dashboards.user_id lookml_dashboards.space.creator_id = folders.dashboards.user_id lookml_dashboards.user_id = folders.dashboards.user_id lookml_dashboards.folder.creator_id = folders.dashboards.folder.creator_id lookml_dashboards.space.creator_id = folders.dashboards.folder.creator_id lookml_dashboards.user_id = folders.dashboards.folder.creator_id lookml_dashboards.folder.creator_id = folders.dashboards.space.creator_id lookml_dashboards.space.creator_id = folders.dashboards.space.creator_id lookml_dashboards.user_id = folders.dashboards.space.creator_id lookml_dashboards.folder.creator_id = folders.looks.deleter_id lookml_dashboards.space.creator_id = folders.looks.deleter_id lookml_dashboards.user_id = folders.looks.deleter_id lookml_dashboards.folder.creator_id = folders.looks.last_updater_id lookml_dashboards.space.creator_id = folders.looks.last_updater_id lookml_dashboards.user_id = folders.looks.last_updater_id lookml_dashboards.folder.creator_id = folders.looks.user.id lookml_dashboards.space.creator_id = folders.looks.user.id lookml_dashboards.user_id = folders.looks.user.id |
| looks |
lookml_dashboards.content_favorite_id = looks.content_favorite_id lookml_dashboards.content_metadata_id = looks.content_metadata_id lookml_dashboards.folder.content_metadata_id = looks.content_metadata_id lookml_dashboards.space.content_metadata_id = looks.content_metadata_id lookml_dashboards.folder.id = looks.folder.id lookml_dashboards.folder.parent_id = looks.folder.id lookml_dashboards.folder.id = looks.folder_id lookml_dashboards.folder.parent_id = looks.folder_id lookml_dashboards.folder.id = looks.folder.parent_id lookml_dashboards.folder.parent_id = looks.folder.parent_id lookml_dashboards.model.id = looks.model.id lookml_dashboards.space.id = looks.space.id lookml_dashboards.space.parent_id = looks.space.id lookml_dashboards.space.id = looks.space.parent_id lookml_dashboards.space.parent_id = looks.space.parent_id lookml_dashboards.space.id = looks.space_id lookml_dashboards.space.parent_id = looks.space_id lookml_dashboards.folder.creator_id = looks.deleter_id lookml_dashboards.space.creator_id = looks.deleter_id lookml_dashboards.user_id = looks.deleter_id lookml_dashboards.folder.creator_id = looks.folder.creator_id lookml_dashboards.space.creator_id = looks.folder.creator_id lookml_dashboards.user_id = looks.folder.creator_id lookml_dashboards.folder.creator_id = looks.user.id lookml_dashboards.space.creator_id = looks.user.id lookml_dashboards.user_id = looks.user.id lookml_dashboards.folder.creator_id = looks.user_id lookml_dashboards.space.creator_id = looks.user_id lookml_dashboards.user_id = looks.user_id |
| content_metadata |
lookml_dashboards.content_metadata_id = content_metadata.id lookml_dashboards.folder.content_metadata_id = content_metadata.id lookml_dashboards.space.content_metadata_id = content_metadata.id lookml_dashboards.content_metadata_id = content_metadata.parent_id lookml_dashboards.folder.content_metadata_id = content_metadata.parent_id lookml_dashboards.space.content_metadata_id = content_metadata.parent_id lookml_dashboards.space.id = content_metadata.space_id lookml_dashboards.space.parent_id = content_metadata.space_id |
| content_metadata_access |
lookml_dashboards.content_metadata_id = content_metadata_access.content_metadata_id lookml_dashboards.folder.content_metadata_id = content_metadata_access.content_metadata_id lookml_dashboards.space.content_metadata_id = content_metadata_access.content_metadata_id |
| content_views |
lookml_dashboards.content_metadata_id = content_views.content_metadata_id lookml_dashboards.folder.content_metadata_id = content_views.content_metadata_id lookml_dashboards.space.content_metadata_id = content_views.content_metadata_id lookml_dashboards.folder.creator_id = content_views.user_id lookml_dashboards.space.creator_id = content_views.user_id lookml_dashboards.user_id = content_views.user_id |
| users |
lookml_dashboards.folder.id = users.home_folder_id lookml_dashboards.folder.parent_id = users.home_folder_id lookml_dashboards.folder.id = users.personal_folder_id lookml_dashboards.folder.parent_id = users.personal_folder_id lookml_dashboards.space.id = users.home_space_id lookml_dashboards.space.parent_id = users.home_space_id lookml_dashboards.space.id = users.personal_space_id lookml_dashboards.space.parent_id = users.personal_space_id lookml_dashboards.folder.creator_id = users.id lookml_dashboards.space.creator_id = users.id lookml_dashboards.user_id = users.id |
| scheduled_plans |
lookml_dashboards.id = scheduled_plans.lookml_dashboard_id lookml_dashboards.folder.creator_id = scheduled_plans.user.id lookml_dashboards.space.creator_id = scheduled_plans.user.id lookml_dashboards.user_id = scheduled_plans.user.id lookml_dashboards.folder.creator_id = scheduled_plans.user_id lookml_dashboards.space.creator_id = scheduled_plans.user_id lookml_dashboards.user_id = scheduled_plans.user_id |
| roles |
lookml_dashboards.model.id = roles.model_set.models |
| connections |
lookml_dashboards.folder.creator_id = connections.user_id lookml_dashboards.space.creator_id = connections.user_id lookml_dashboards.user_id = connections.user_id |
| user_login_lockouts |
lookml_dashboards.folder.creator_id = user_login_lockouts.user_id lookml_dashboards.space.creator_id = user_login_lockouts.user_id lookml_dashboards.user_id = user_login_lockouts.user_id |
|
content_favorite_id STRING |
||||||||||||||
|
content_metadata_id STRING |
||||||||||||||
|
description STRING |
||||||||||||||
|
folder OBJECT
|
||||||||||||||
|
hidden BOOLEAN |
||||||||||||||
|
id
STRING |
||||||||||||||
|
model OBJECT
|
||||||||||||||
|
query_timezone STRING |
||||||||||||||
|
readonly BOOLEAN |
||||||||||||||
|
refresh_interval STRING |
||||||||||||||
|
refresh_interval_to_i INTEGER |
||||||||||||||
|
space OBJECT
|
||||||||||||||
|
title STRING |
||||||||||||||
|
user_id STRING |
lookml_models
The lookml_models table contains information about all LookML models in your Looker instance.
|
Full Table |
|
|
Primary Keys |
name project_name |
| Useful links |
|
allowed_db_connection_names ARRAY |
|||||
|
explores ARRAY
|
|||||
|
has_content BOOLEAN |
|||||
|
label STRING |
|||||
|
name
STRING |
|||||
|
project_name
STRING |
|||||
|
unlimited_db_connections BOOLEAN |
looks
The looks table contains information about all active looks in your Looker account. Note: Based on Looker’s documentation, this table doesn’t include soft-deleted looks.
|
Full Table |
|
|
Primary Key |
id |
| Useful links |
| Join looks with | on |
|---|---|
| content_favorites |
looks.content_favorite_id = content_favorites.id looks.content_favorite_id = content_favorites.dashboard.content_favorite_id looks.content_metadata_id = content_favorites.content_metadata_id looks.content_metadata_id = content_favorites.dashboard.content_metadata_id looks.content_metadata_id = content_favorites.dashboard.folder.content_metadata_id looks.content_metadata_id = content_favorites.dashboard.space.content_metadata_id looks.content_metadata_id = content_favorites.look.content_metadata_id looks.folder.id = content_favorites.dashboard.folder.id looks.folder_id = content_favorites.dashboard.folder.id looks.folder.parent_id = content_favorites.dashboard.folder.id looks.folder.id = content_favorites.dashboard.folder.parent_id looks.folder_id = content_favorites.dashboard.folder.parent_id looks.folder.parent_id = content_favorites.dashboard.folder.parent_id looks.id = content_favorites.look_id looks.id = content_favorites.look.id looks.model.id = content_favorites.dashboard.model.id looks.space.id = content_favorites.dashboard.space.id looks.space.parent_id = content_favorites.dashboard.space.id looks.space_id = content_favorites.dashboard.space.id looks.space.id = content_favorites.dashboard.space.parent_id looks.space.parent_id = content_favorites.dashboard.space.parent_id looks.space_id = content_favorites.dashboard.space.parent_id looks.deleter_id = content_favorites.dashboard.folder.creator_id looks.folder.creator_id = content_favorites.dashboard.folder.creator_id looks.user.id = content_favorites.dashboard.folder.creator_id looks.user_id = content_favorites.dashboard.folder.creator_id looks.deleter_id = content_favorites.dashboard.space.creator_id looks.folder.creator_id = content_favorites.dashboard.space.creator_id looks.user.id = content_favorites.dashboard.space.creator_id looks.user_id = content_favorites.dashboard.space.creator_id looks.deleter_id = content_favorites.user_id looks.folder.creator_id = content_favorites.user_id looks.user.id = content_favorites.user_id looks.user_id = content_favorites.user_id |
| dashboard_elements |
looks.content_favorite_id = dashboard_elements.look.content_favorite_id looks.content_metadata_id = dashboard_elements.look.content_metadata_id looks.content_metadata_id = dashboard_elements.look.folder.content_metadata_id looks.content_metadata_id = dashboard_elements.look.space.content_metadata_id looks.folder.id = dashboard_elements.look.folder.id looks.folder_id = dashboard_elements.look.folder.id looks.folder.parent_id = dashboard_elements.look.folder.id looks.folder.id = dashboard_elements.look.folder.parent_id looks.folder_id = dashboard_elements.look.folder.parent_id looks.folder.parent_id = dashboard_elements.look.folder.parent_id looks.folder.id = dashboard_elements.look.folder_id looks.folder_id = dashboard_elements.look.folder_id looks.folder.parent_id = dashboard_elements.look.folder_id looks.id = dashboard_elements.look.id looks.id = dashboard_elements.look_id looks.model.id = dashboard_elements.look.model.id looks.query_id = dashboard_elements.look.query.id looks.query_id = dashboard_elements.look.query_id looks.query_id = dashboard_elements.query.id looks.query_id = dashboard_elements.query_id looks.query_id = dashboard_elements.result_maker.query.id looks.query_id = dashboard_elements.result_maker.query_id looks.space.id = dashboard_elements.look.space.id looks.space.parent_id = dashboard_elements.look.space.id looks.space_id = dashboard_elements.look.space.id looks.space.id = dashboard_elements.look.space.parent_id looks.space.parent_id = dashboard_elements.look.space.parent_id looks.space_id = dashboard_elements.look.space.parent_id looks.deleter_id = dashboard_elements.look.deleter_id looks.folder.creator_id = dashboard_elements.look.deleter_id looks.user.id = dashboard_elements.look.deleter_id looks.user_id = dashboard_elements.look.deleter_id looks.deleter_id = dashboard_elements.look.folder.creator_id looks.folder.creator_id = dashboard_elements.look.folder.creator_id looks.user.id = dashboard_elements.look.folder.creator_id looks.user_id = dashboard_elements.look.folder.creator_id looks.deleter_id = dashboard_elements.look.last_updater_id looks.folder.creator_id = dashboard_elements.look.last_updater_id looks.user.id = dashboard_elements.look.last_updater_id looks.user_id = dashboard_elements.look.last_updater_id looks.deleter_id = dashboard_elements.look.space.creator_id looks.folder.creator_id = dashboard_elements.look.space.creator_id looks.user.id = dashboard_elements.look.space.creator_id looks.user_id = dashboard_elements.look.space.creator_id looks.deleter_id = dashboard_elements.look.user.id looks.folder.creator_id = dashboard_elements.look.user.id looks.user.id = dashboard_elements.look.user.id looks.user_id = dashboard_elements.look.user.id looks.deleter_id = dashboard_elements.look.user_id looks.folder.creator_id = dashboard_elements.look.user_id looks.user.id = dashboard_elements.look.user_id looks.user_id = dashboard_elements.look.user_id |
| dashboards |
looks.content_favorite_id = dashboards.content_favorite_id looks.content_metadata_id = dashboards.content_metadata_id looks.content_metadata_id = dashboards.folder.content_metadata_id looks.content_metadata_id = dashboards.space.content_metadata_id looks.folder.id = dashboards.folder.id looks.folder_id = dashboards.folder.id looks.folder.parent_id = dashboards.folder.id looks.folder.id = dashboards.folder.parent_id looks.folder_id = dashboards.folder.parent_id looks.folder.parent_id = dashboards.folder.parent_id looks.model.id = dashboards.model.id looks.space.id = dashboards.space.id looks.space.parent_id = dashboards.space.id looks.space_id = dashboards.space.id looks.space.id = dashboards.space.parent_id looks.space.parent_id = dashboards.space.parent_id looks.space_id = dashboards.space.parent_id looks.deleter_id = dashboards.space.creator_id looks.folder.creator_id = dashboards.space.creator_id looks.user.id = dashboards.space.creator_id looks.user_id = dashboards.space.creator_id looks.deleter_id = dashboards.user_id looks.folder.creator_id = dashboards.user_id looks.user.id = dashboards.user_id looks.user_id = dashboards.user_id |
| folders |
looks.content_favorite_id = folders.dashboards.content_favorite_id looks.content_favorite_id = folders.looks.content_favorite_id looks.content_metadata_id = folders.dashboards.folder.content_metadata_id looks.content_metadata_id = folders.dashboards.space.content_metadata_id looks.content_metadata_id = folders.looks.content_metadata_id looks.content_metadata_id = folders.looks.folder.content_metadata_id looks.folder.id = folders.id looks.folder_id = folders.id looks.folder.parent_id = folders.id looks.folder.id = folders.dashboards.folder.id looks.folder_id = folders.dashboards.folder.id looks.folder.parent_id = folders.dashboards.folder.id looks.folder.id = folders.dashboards.folder.parent_id looks.folder_id = folders.dashboards.folder.parent_id looks.folder.parent_id = folders.dashboards.folder.parent_id looks.folder.id = folders.looks.folder.id looks.folder_id = folders.looks.folder.id looks.folder.parent_id = folders.looks.folder.id looks.folder.id = folders.looks.folder.parent_id looks.folder_id = folders.looks.folder.parent_id looks.folder.parent_id = folders.looks.folder.parent_id looks.folder.id = folders.parent_id looks.folder_id = folders.parent_id looks.folder.parent_id = folders.parent_id looks.id = folders.looks.id looks.model.id = folders.dashboards.model.id looks.model.id = folders.looks.model.id looks.query_id = folders.looks.query_id looks.space.id = folders.dashboards.space.id looks.space.parent_id = folders.dashboards.space.id looks.space_id = folders.dashboards.space.id looks.space.id = folders.dashboards.space.parent_id looks.space.parent_id = folders.dashboards.space.parent_id looks.space_id = folders.dashboards.space.parent_id looks.space.id = folders.looks.space.id looks.space.parent_id = folders.looks.space.id looks.space_id = folders.looks.space.id looks.space.id = folders.looks.space.parent_id looks.space.parent_id = folders.looks.space.parent_id looks.space_id = folders.looks.space.parent_id looks.space.id = folders.looks.space_id looks.space.parent_id = folders.looks.space_id looks.space_id = folders.looks.space_id looks.deleter_id = folders.creator_id looks.folder.creator_id = folders.creator_id looks.user.id = folders.creator_id looks.user_id = folders.creator_id looks.deleter_id = folders.dashboards.user_id looks.folder.creator_id = folders.dashboards.user_id looks.user.id = folders.dashboards.user_id looks.user_id = folders.dashboards.user_id looks.deleter_id = folders.dashboards.folder.creator_id looks.folder.creator_id = folders.dashboards.folder.creator_id looks.user.id = folders.dashboards.folder.creator_id looks.user_id = folders.dashboards.folder.creator_id looks.deleter_id = folders.dashboards.space.creator_id looks.folder.creator_id = folders.dashboards.space.creator_id looks.user.id = folders.dashboards.space.creator_id looks.user_id = folders.dashboards.space.creator_id looks.deleter_id = folders.looks.deleter_id looks.folder.creator_id = folders.looks.deleter_id looks.user.id = folders.looks.deleter_id looks.user_id = folders.looks.deleter_id looks.deleter_id = folders.looks.last_updater_id looks.folder.creator_id = folders.looks.last_updater_id looks.user.id = folders.looks.last_updater_id looks.user_id = folders.looks.last_updater_id looks.deleter_id = folders.looks.user.id looks.folder.creator_id = folders.looks.user.id looks.user.id = folders.looks.user.id looks.user_id = folders.looks.user.id |
| lookml_dashboards |
looks.content_favorite_id = lookml_dashboards.content_favorite_id looks.content_metadata_id = lookml_dashboards.content_metadata_id looks.content_metadata_id = lookml_dashboards.folder.content_metadata_id looks.content_metadata_id = lookml_dashboards.space.content_metadata_id looks.folder.id = lookml_dashboards.folder.id looks.folder_id = lookml_dashboards.folder.id looks.folder.parent_id = lookml_dashboards.folder.id looks.folder.id = lookml_dashboards.folder.parent_id looks.folder_id = lookml_dashboards.folder.parent_id looks.folder.parent_id = lookml_dashboards.folder.parent_id looks.model.id = lookml_dashboards.model.id looks.space.id = lookml_dashboards.space.id looks.space.parent_id = lookml_dashboards.space.id looks.space_id = lookml_dashboards.space.id looks.space.id = lookml_dashboards.space.parent_id looks.space.parent_id = lookml_dashboards.space.parent_id looks.space_id = lookml_dashboards.space.parent_id looks.deleter_id = lookml_dashboards.folder.creator_id looks.folder.creator_id = lookml_dashboards.folder.creator_id looks.user.id = lookml_dashboards.folder.creator_id looks.user_id = lookml_dashboards.folder.creator_id looks.deleter_id = lookml_dashboards.space.creator_id looks.folder.creator_id = lookml_dashboards.space.creator_id looks.user.id = lookml_dashboards.space.creator_id looks.user_id = lookml_dashboards.space.creator_id looks.deleter_id = lookml_dashboards.user_id looks.folder.creator_id = lookml_dashboards.user_id looks.user.id = lookml_dashboards.user_id looks.user_id = lookml_dashboards.user_id |
| content_metadata |
looks.content_metadata_id = content_metadata.id looks.content_metadata_id = content_metadata.parent_id looks.id = content_metadata.look_id looks.space.id = content_metadata.space_id looks.space.parent_id = content_metadata.space_id looks.space_id = content_metadata.space_id |
| content_metadata_access |
looks.content_metadata_id = content_metadata_access.content_metadata_id |
| content_views |
looks.content_metadata_id = content_views.content_metadata_id looks.id = content_views.look_id looks.deleter_id = content_views.user_id looks.folder.creator_id = content_views.user_id looks.user.id = content_views.user_id looks.user_id = content_views.user_id |
| users |
looks.folder.id = users.home_folder_id looks.folder_id = users.home_folder_id looks.folder.parent_id = users.home_folder_id looks.folder.id = users.personal_folder_id looks.folder_id = users.personal_folder_id looks.folder.parent_id = users.personal_folder_id looks.space.id = users.home_space_id looks.space.parent_id = users.home_space_id looks.space_id = users.home_space_id looks.space.id = users.personal_space_id looks.space.parent_id = users.personal_space_id looks.space_id = users.personal_space_id looks.deleter_id = users.id looks.folder.creator_id = users.id looks.user.id = users.id looks.user_id = users.id |
| scheduled_plans |
looks.id = scheduled_plans.look_id looks.query_id = scheduled_plans.query_id looks.deleter_id = scheduled_plans.user.id looks.folder.creator_id = scheduled_plans.user.id looks.user.id = scheduled_plans.user.id looks.user_id = scheduled_plans.user.id looks.deleter_id = scheduled_plans.user_id looks.folder.creator_id = scheduled_plans.user_id looks.user.id = scheduled_plans.user_id looks.user_id = scheduled_plans.user_id |
| roles |
looks.model.id = roles.model_set.models |
| queries |
looks.query_id = queries.id |
| connections |
looks.deleter_id = connections.user_id looks.folder.creator_id = connections.user_id looks.user.id = connections.user_id looks.user_id = connections.user_id |
| user_login_lockouts |
looks.deleter_id = user_login_lockouts.user_id looks.folder.creator_id = user_login_lockouts.user_id looks.user.id = user_login_lockouts.user_id looks.user_id = user_login_lockouts.user_id |
|
content_favorite_id STRING |
||||||||||||||
|
content_metadata_id STRING |
||||||||||||||
|
created_at DATE-TIME |
||||||||||||||
|
deleted BOOLEAN |
||||||||||||||
|
deleted_at DATE-TIME |
||||||||||||||
|
deleter_id STRING |
||||||||||||||
|
description STRING |
||||||||||||||
|
embed_url STRING |
||||||||||||||
|
excel_file_url STRING |
||||||||||||||
|
favorite_count INTEGER |
||||||||||||||
|
folder OBJECT
|
||||||||||||||
|
folder_id STRING |
||||||||||||||
|
google_spreadsheet_formula STRING |
||||||||||||||
|
id
STRING |
||||||||||||||
|
image_embed_url STRING |
||||||||||||||
|
is_run_on_load BOOLEAN |
||||||||||||||
|
last_accessed_at DATE-TIME |
||||||||||||||
|
last_updater_id STRING |
||||||||||||||
|
last_viewed_at DATE-TIME |
||||||||||||||
|
model OBJECT
|
||||||||||||||
|
public BOOLEAN |
||||||||||||||
|
public_slug STRING |
||||||||||||||
|
public_url STRING |
||||||||||||||
|
query_id STRING |
||||||||||||||
|
short_url STRING |
||||||||||||||
|
space OBJECT
|
||||||||||||||
|
space_id STRING |
||||||||||||||
|
title STRING |
||||||||||||||
|
updated_at DATE-TIME |
||||||||||||||
|
user OBJECT
|
||||||||||||||
|
user_id STRING |
||||||||||||||
|
view_count INTEGER |
merge_queries
The merge_queries table contains info about the merge queries in your Looker instance.
|
Full Table |
|
|
Primary Key |
id |
| Useful links |
|
column_limit STRING |
|||||
|
dynamic_fields STRING |
|||||
|
id
STRING |
|||||
|
pivots ARRAY |
|||||
|
result_maker_id STRING |
|||||
|
sorts ARRAY |
|||||
|
source_queries ARRAY
|
|||||
|
total BOOLEAN |
|||||
|
vis_config OBJECT |
model_sets
The model_sets table contains info about the role model sets in your Looker instance.
|
Full Table |
|
|
Primary Key |
id |
| Useful links |
| Join model_sets with | on |
|---|---|
| roles |
model_sets.id = roles.model_set.id model_sets.id = roles.model_set_id |
|
all_access BOOLEAN |
|
built_in BOOLEAN |
|
id
STRING |
|
models ARRAY |
|
name STRING |
|
url STRING |
models
The models table contains information about individual models in your Looker account.
|
Full Table |
|
|
Primary Keys |
name project_name |
| Useful links |
|
allowed_db_connection_names ARRAY |
|||||
|
explores ARRAY
|
|||||
|
has_content BOOLEAN |
|||||
|
label STRING |
|||||
|
name
STRING |
|||||
|
project_name
STRING |
|||||
|
unlimited_db_connections BOOLEAN |
permission_sets
The permission_sets table contains info about the role permission sets in your Looker instance.
|
Full Table |
|
|
Primary Key |
id |
| Useful links |
| Join permission_sets with | on |
|---|---|
| roles |
permission_sets.id = roles.permission_set_id permission_sets.id = roles.id |
|
all_access BOOLEAN |
|
built_in BOOLEAN |
|
id
STRING |
|
name STRING |
|
permissions ARRAY |
|
url STRING |
permissions
The permissions table contains info about the permissions listed in your Looker account.
|
Full Table |
|
|
Primary Key |
permission |
| Useful links |
|
description STRING |
|
parent STRING |
|
permission
STRING |
project_files
The project_files table contains info about the files associated with projects in your Looker instance.
|
Full Table |
|
|
Primary Key |
id |
| Useful links |
| Join project_files with | on |
|---|---|
| git_branches |
project_files.project_id = git_branches.project_id |
| projects |
project_files.project_id = projects.id |
| workspaces |
project_files.project_id = workspaces.projects.id |
|
editable BOOLEAN |
||||
|
extension STRING |
||||
|
git_status OBJECT
|
||||
|
id
STRING |
||||
|
mime_type STRING |
||||
|
path STRING |
||||
|
project_id STRING |
||||
|
title STRING |
||||
|
type STRING |
projects
The projects table contains info about the projects in your Looker instance.
|
Full Table |
|
|
Primary Key |
id |
| Useful links |
| Join projects with | on |
|---|---|
| git_branches |
projects.id = git_branches.project_id |
| project_files |
projects.id = project_files.project_id |
| workspaces |
projects.id = workspaces.projects.id |
|
allow_warnings BOOLEAN |
|
deploy_secret STRING |
|
folders_enabled BOOLEAN |
|
git_password STRING |
|
git_password_user_attribute STRING |
|
git_remote_url STRING |
|
git_service_name STRING |
|
git_username STRING |
|
git_username_user_attribute STRING |
|
id
STRING |
|
is_example BOOLEAN |
|
name STRING |
|
pull_request_mode STRING |
|
unset_deploy_secret BOOLEAN |
|
uses_git BOOLEAN |
|
validation_required BOOLEAN |
queries
The queries table contains info about the queries that exist in your Looker instance.
|
Full Table |
|
|
Primary Key |
id |
| Useful links |
| Join queries with | on |
|---|---|
| dashboard_elements |
queries.id = dashboard_elements.look.query.id queries.id = dashboard_elements.look.query_id queries.id = dashboard_elements.query.id queries.id = dashboard_elements.query_id queries.id = dashboard_elements.result_maker.query.id queries.id = dashboard_elements.result_maker.query_id |
| folders |
queries.id = folders.looks.query_id |
| looks |
queries.id = looks.query_id |
| scheduled_plans |
queries.id = scheduled_plans.query_id |
|
client_id STRING |
|
column_limit STRING |
|
dynamic_fields STRING |
|
expanded_share_url STRING |
|
fields ARRAY |
|
fill_fields ARRAY |
|
filter_config OBJECT |
|
filter_expression STRING |
|
filters OBJECT |
|
has_table_calculations BOOLEAN |
|
id
STRING |
|
limit STRING |
|
model STRING |
|
pivots ARRAY |
|
query_timezone STRING |
|
row_total STRING |
|
runtime NUMBER |
|
share_url STRING |
|
slug STRING |
|
sorts ARRAY |
|
subtotals ARRAY |
|
total BOOLEAN |
|
url STRING |
|
view STRING |
|
vis_config OBJECT |
|
visible_ui_sections STRING |
query_history
The query_history table contains query history data pulled from Looker’s History Explore, or i__looker database, for queries run in the past seven days.
To extract this data, Sttich will submit a query with the properties in this file to the Looker API. The results of Stitch’s query are then extracted and replicated to your destination.
Note: Stitch’s Looker integration only replicates the past seven days of query history at any given time.
|
Full Table |
|
|
Primary Keys |
dims_hash_key history_created_date query_id |
| Useful links |
|
dashboard_id STRING |
|
dims_hash_key
STRING |
|
history_created_date
STRING |
|
history_query_run_count INTEGER |
|
history_total_runtime NUMBER |
|
look_id STRING |
|
query_id
STRING |
|
query_model STRING |
|
query_view STRING |
|
space_id STRING |
|
user_id STRING |
role_groups
The role_groups table contains info about the role groups in your Looker instance.
|
Full Table |
|
|
Primary Key |
id |
| Useful links |
|
can_add_to_content_metadata BOOLEAN |
|
contains_current_user BOOLEAN |
|
external_group_id STRING |
|
externally_managed BOOLEAN |
|
id
STRING |
|
include_by_default BOOLEAN |
|
name STRING |
|
role_id STRING |
|
user_count INTEGER |
roles
The roles table contains info about the user roles in your Looker instance.
|
Full Table |
|
|
Primary Key |
id |
| Useful links |
| Join roles with | on |
|---|---|
| model_sets |
roles.model_set.id = model_sets.id roles.model_set_id = model_sets.id |
| content_favorites |
roles.model_set.models = content_favorites.dashboard.model.id |
| dashboard_elements |
roles.model_set.models = dashboard_elements.look.model.id |
| dashboards |
roles.model_set.models = dashboards.model.id |
| folders |
roles.model_set.models = folders.dashboards.model.id roles.model_set.models = folders.looks.model.id |
| lookml_dashboards |
roles.model_set.models = lookml_dashboards.model.id |
| looks |
roles.model_set.models = looks.model.id |
| permission_sets |
roles.permission_set_id = permission_sets.id roles.id = permission_sets.id |
| role_groups |
roles.id = role_groups.role_id |
| users |
roles.id = users.role_ids |
|
id
STRING |
||||||
|
model_set OBJECT
|
||||||
|
model_set_id STRING |
||||||
|
name STRING |
||||||
|
permission_set OBJECT
|
||||||
|
permission_set_id STRING |
||||||
|
url STRING |
||||||
|
users_url STRING |
scheduled_plans
The scheduled_plans table contains info about all scheduled plans in your Looker instance.
|
Full Table |
|
|
Primary Key |
id |
| Useful links |
| Join scheduled_plans with | on |
|---|---|
| content_favorites |
scheduled_plans.dashboard_id = content_favorites.dashboard.id scheduled_plans.dashboard_id = content_favorites.dashboard_id scheduled_plans.look_id = content_favorites.look_id scheduled_plans.look_id = content_favorites.look.id scheduled_plans.user.id = content_favorites.dashboard.folder.creator_id scheduled_plans.user_id = content_favorites.dashboard.folder.creator_id scheduled_plans.user.id = content_favorites.dashboard.space.creator_id scheduled_plans.user_id = content_favorites.dashboard.space.creator_id scheduled_plans.user.id = content_favorites.user_id scheduled_plans.user_id = content_favorites.user_id |
| content_metadata |
scheduled_plans.dashboard_id = content_metadata.dashboard_id scheduled_plans.look_id = content_metadata.look_id |
| content_views |
scheduled_plans.dashboard_id = content_views.dashboard_id scheduled_plans.look_id = content_views.look_id scheduled_plans.user.id = content_views.user_id scheduled_plans.user_id = content_views.user_id |
| dashboard_elements |
scheduled_plans.dashboard_id = dashboard_elements.dashboard_id scheduled_plans.look_id = dashboard_elements.look.id scheduled_plans.look_id = dashboard_elements.look_id scheduled_plans.query_id = dashboard_elements.look.query.id scheduled_plans.query_id = dashboard_elements.look.query_id scheduled_plans.query_id = dashboard_elements.query.id scheduled_plans.query_id = dashboard_elements.query_id scheduled_plans.query_id = dashboard_elements.result_maker.query.id scheduled_plans.query_id = dashboard_elements.result_maker.query_id scheduled_plans.user.id = dashboard_elements.look.deleter_id scheduled_plans.user_id = dashboard_elements.look.deleter_id scheduled_plans.user.id = dashboard_elements.look.folder.creator_id scheduled_plans.user_id = dashboard_elements.look.folder.creator_id scheduled_plans.user.id = dashboard_elements.look.last_updater_id scheduled_plans.user_id = dashboard_elements.look.last_updater_id scheduled_plans.user.id = dashboard_elements.look.space.creator_id scheduled_plans.user_id = dashboard_elements.look.space.creator_id scheduled_plans.user.id = dashboard_elements.look.user.id scheduled_plans.user_id = dashboard_elements.look.user.id scheduled_plans.user.id = dashboard_elements.look.user_id scheduled_plans.user_id = dashboard_elements.look.user_id |
| dashboard_filters |
scheduled_plans.dashboard_id = dashboard_filters.dashboard_id |
| dashboard_layouts |
scheduled_plans.dashboard_id = dashboard_layouts.dashboard_id |
| dashboards |
scheduled_plans.dashboard_id = dashboards.id scheduled_plans.user.id = dashboards.space.creator_id scheduled_plans.user_id = dashboards.space.creator_id scheduled_plans.user.id = dashboards.user_id scheduled_plans.user_id = dashboards.user_id |
| folders |
scheduled_plans.dashboard_id = folders.dashboards.id scheduled_plans.look_id = folders.looks.id scheduled_plans.query_id = folders.looks.query_id scheduled_plans.user.id = folders.creator_id scheduled_plans.user_id = folders.creator_id scheduled_plans.user.id = folders.dashboards.user_id scheduled_plans.user_id = folders.dashboards.user_id scheduled_plans.user.id = folders.dashboards.folder.creator_id scheduled_plans.user_id = folders.dashboards.folder.creator_id scheduled_plans.user.id = folders.dashboards.space.creator_id scheduled_plans.user_id = folders.dashboards.space.creator_id scheduled_plans.user.id = folders.looks.deleter_id scheduled_plans.user_id = folders.looks.deleter_id scheduled_plans.user.id = folders.looks.last_updater_id scheduled_plans.user_id = folders.looks.last_updater_id scheduled_plans.user.id = folders.looks.user.id scheduled_plans.user_id = folders.looks.user.id |
| looks |
scheduled_plans.look_id = looks.id scheduled_plans.query_id = looks.query_id scheduled_plans.user.id = looks.deleter_id scheduled_plans.user_id = looks.deleter_id scheduled_plans.user.id = looks.folder.creator_id scheduled_plans.user_id = looks.folder.creator_id scheduled_plans.user.id = looks.user.id scheduled_plans.user_id = looks.user.id scheduled_plans.user.id = looks.user_id scheduled_plans.user_id = looks.user_id |
| lookml_dashboards |
scheduled_plans.lookml_dashboard_id = lookml_dashboards.id scheduled_plans.user.id = lookml_dashboards.folder.creator_id scheduled_plans.user_id = lookml_dashboards.folder.creator_id scheduled_plans.user.id = lookml_dashboards.space.creator_id scheduled_plans.user_id = lookml_dashboards.space.creator_id scheduled_plans.user.id = lookml_dashboards.user_id scheduled_plans.user_id = lookml_dashboards.user_id |
| queries |
scheduled_plans.query_id = queries.id |
| connections |
scheduled_plans.user.id = connections.user_id scheduled_plans.user_id = connections.user_id |
| user_login_lockouts |
scheduled_plans.user.id = user_login_lockouts.user_id scheduled_plans.user_id = user_login_lockouts.user_id |
| users |
scheduled_plans.user.id = users.id scheduled_plans.user_id = users.id |
|
color_theme STRING |
|||||||||||
|
created_at DATE-TIME |
|||||||||||
|
crontab STRING |
|||||||||||
|
dashboard_filters STRING |
|||||||||||
|
dashboard_id STRING |
|||||||||||
|
datagroup STRING |
|||||||||||
|
embed BOOLEAN |
|||||||||||
|
enabled BOOLEAN |
|||||||||||
|
filters_string STRING |
|||||||||||
|
id
STRING |
|||||||||||
|
include_links BOOLEAN |
|||||||||||
|
last_run_at DATE-TIME |
|||||||||||
|
long_tables BOOLEAN |
|||||||||||
|
look_id STRING |
|||||||||||
|
lookml_dashboard_id STRING |
|||||||||||
|
name STRING |
|||||||||||
|
next_run_at DATE-TIME |
|||||||||||
|
pdf_landscape BOOLEAN |
|||||||||||
|
pdf_paper_size STRING |
|||||||||||
|
query_id STRING |
|||||||||||
|
require_change BOOLEAN |
|||||||||||
|
require_no_results BOOLEAN |
|||||||||||
|
require_results BOOLEAN |
|||||||||||
|
run_as_recipient BOOLEAN |
|||||||||||
|
run_once BOOLEAN |
|||||||||||
|
scheduled_plan_destination ARRAY
|
|||||||||||
|
send_all_results BOOLEAN |
|||||||||||
|
timezone STRING |
|||||||||||
|
title STRING |
|||||||||||
|
updated_at DATE-TIME |
|||||||||||
|
user OBJECT
|
|||||||||||
|
user_id STRING |
themes
The themes table contains info about the themes in your Looker instance.
|
Full Table |
|
|
Primary Key |
id |
| Useful links |
| Join themes with | on |
|---|---|
| color_collections |
themes.settings.color_collection_id = color_collections.id |
|
begin_at DATE-TIME |
|||||||||||||||
|
end_at DATE-TIME |
|||||||||||||||
|
id
STRING |
|||||||||||||||
|
name STRING |
|||||||||||||||
|
settings OBJECT
|
user_attribute_group_values
The user_attribute_group_values table contains info about the values of user attributes defined by user groups in your Looker instance.
|
Full Table |
|
|
Primary Key |
id |
| Useful links |
| Join user_attribute_group_values with | on |
|---|---|
| content_metadata_access |
user_attribute_group_values.group_id = content_metadata_access.group_id |
| content_views |
user_attribute_group_values.group_id = content_views.group_id |
| groups |
user_attribute_group_values.group_id = groups.id |
| groups_in_group |
user_attribute_group_values.group_id = groups_in_group.id user_attribute_group_values.group_id = groups_in_group.parent_group_id |
| users |
user_attribute_group_values.group_id = users.group_ids |
| user_attributes |
user_attribute_group_values.user_attribute_id = user_attributes.id |
|
group_id STRING |
|
id
STRING |
|
rank INTEGER |
|
user_attribute_id STRING |
|
value STRING |
|
value_is_hidden BOOLEAN |
user_attribute_values
The user_attribute_values table contains info about the values for user attributes defined in your Looker instance.
|
Full Table |
|
|
Primary Keys |
user_attribute_id user_id |
| Useful links |
|
hidden_value_domain_whitelist STRING |
|
label STRING |
|
name STRING |
|
rank INTEGER |
|
source STRING |
|
user_attribute_id
STRING |
|
user_can_edit BOOLEAN |
|
user_id
STRING |
|
value STRING |
|
value_is_hidden BOOLEAN |
user_attributes
The user_attributes table contains info about user attributes in your Looker instance.
|
Full Table |
|
|
Primary Key |
id |
| Useful links |
| Join user_attributes with | on |
|---|---|
| user_attribute_group_values |
user_attributes.id = user_attribute_group_values.user_attribute_id |
|
default_value STRING |
|
hidden_value_domain_whitelist STRING |
|
id
STRING |
|
is_permanent BOOLEAN |
|
is_system BOOLEAN |
|
label STRING |
|
name STRING |
|
type STRING |
|
user_can_edit BOOLEAN |
|
user_can_view BOOLEAN |
|
value_is_hidden BOOLEAN |
user_login_lockouts
The user_login_lockouts table contains info about lockouts for user logins associated with your Looker instance.
|
Full Table |
|
|
Primary Key |
key |
| Useful links |
| Join user_login_lockouts with | on |
|---|---|
| connections |
user_login_lockouts.user_id = connections.user_id |
| content_favorites |
user_login_lockouts.user_id = content_favorites.dashboard.folder.creator_id user_login_lockouts.user_id = content_favorites.dashboard.space.creator_id user_login_lockouts.user_id = content_favorites.user_id |
| content_views |
user_login_lockouts.user_id = content_views.user_id |
| dashboard_elements |
user_login_lockouts.user_id = dashboard_elements.look.deleter_id user_login_lockouts.user_id = dashboard_elements.look.folder.creator_id user_login_lockouts.user_id = dashboard_elements.look.last_updater_id user_login_lockouts.user_id = dashboard_elements.look.space.creator_id user_login_lockouts.user_id = dashboard_elements.look.user.id user_login_lockouts.user_id = dashboard_elements.look.user_id |
| dashboards |
user_login_lockouts.user_id = dashboards.space.creator_id user_login_lockouts.user_id = dashboards.user_id |
| folders |
user_login_lockouts.user_id = folders.creator_id user_login_lockouts.user_id = folders.dashboards.user_id user_login_lockouts.user_id = folders.dashboards.folder.creator_id user_login_lockouts.user_id = folders.dashboards.space.creator_id user_login_lockouts.user_id = folders.looks.deleter_id user_login_lockouts.user_id = folders.looks.last_updater_id user_login_lockouts.user_id = folders.looks.user.id |
| lookml_dashboards |
user_login_lockouts.user_id = lookml_dashboards.folder.creator_id user_login_lockouts.user_id = lookml_dashboards.space.creator_id user_login_lockouts.user_id = lookml_dashboards.user_id |
| looks |
user_login_lockouts.user_id = looks.deleter_id user_login_lockouts.user_id = looks.folder.creator_id user_login_lockouts.user_id = looks.user.id user_login_lockouts.user_id = looks.user_id |
| scheduled_plans |
user_login_lockouts.user_id = scheduled_plans.user.id user_login_lockouts.user_id = scheduled_plans.user_id |
| users |
user_login_lockouts.user_id = users.id |
|
auth_type STRING |
|
STRING |
|
fail_count INTEGER |
|
full_name STRING |
|
ip STRING |
|
key
STRING |
|
lockout_at DATE-TIME |
|
remote_id STRING |
|
user_id STRING |
user_sessions
The user_sessions table contains info about user web login sessions associated with your Looker instance.
|
Full Table |
|
|
Primary Key |
id |
| Useful links |
| Join user_sessions with | on |
|---|---|
| users |
user_sessions.id = users.sessions.id |
|
browser STRING |
|
city STRING |
|
country STRING |
|
created_at STRING |
|
credentials_type STRING |
|
expires_at STRING |
|
extended_at STRING |
|
extended_count INTEGER |
|
id
STRING |
|
ip_address STRING |
|
operating_system STRING |
|
state STRING |
|
sudo_user_id STRING |
|
url STRING |
users
The users table contains info about users associated with your Looker account.
|
Full Table |
|
|
Primary Key |
id |
| Useful links |
| Join users with | on |
|---|---|
| content_favorites |
users.home_folder_id = content_favorites.dashboard.folder.id users.personal_folder_id = content_favorites.dashboard.folder.id users.home_folder_id = content_favorites.dashboard.folder.parent_id users.personal_folder_id = content_favorites.dashboard.folder.parent_id users.home_space_id = content_favorites.dashboard.space.id users.personal_space_id = content_favorites.dashboard.space.id users.home_space_id = content_favorites.dashboard.space.parent_id users.personal_space_id = content_favorites.dashboard.space.parent_id users.id = content_favorites.dashboard.folder.creator_id users.id = content_favorites.dashboard.space.creator_id users.id = content_favorites.user_id |
| dashboard_elements |
users.home_folder_id = dashboard_elements.look.folder.id users.personal_folder_id = dashboard_elements.look.folder.id users.home_folder_id = dashboard_elements.look.folder.parent_id users.personal_folder_id = dashboard_elements.look.folder.parent_id users.home_folder_id = dashboard_elements.look.folder_id users.personal_folder_id = dashboard_elements.look.folder_id users.home_space_id = dashboard_elements.look.space.id users.personal_space_id = dashboard_elements.look.space.id users.home_space_id = dashboard_elements.look.space.parent_id users.personal_space_id = dashboard_elements.look.space.parent_id users.id = dashboard_elements.look.deleter_id users.id = dashboard_elements.look.folder.creator_id users.id = dashboard_elements.look.last_updater_id users.id = dashboard_elements.look.space.creator_id users.id = dashboard_elements.look.user.id users.id = dashboard_elements.look.user_id |
| dashboards |
users.home_folder_id = dashboards.folder.id users.personal_folder_id = dashboards.folder.id users.home_folder_id = dashboards.folder.parent_id users.personal_folder_id = dashboards.folder.parent_id users.home_space_id = dashboards.space.id users.personal_space_id = dashboards.space.id users.home_space_id = dashboards.space.parent_id users.personal_space_id = dashboards.space.parent_id users.id = dashboards.space.creator_id users.id = dashboards.user_id |
| folders |
users.home_folder_id = folders.id users.personal_folder_id = folders.id users.home_folder_id = folders.dashboards.folder.id users.personal_folder_id = folders.dashboards.folder.id users.home_folder_id = folders.dashboards.folder.parent_id users.personal_folder_id = folders.dashboards.folder.parent_id users.home_folder_id = folders.looks.folder.id users.personal_folder_id = folders.looks.folder.id users.home_folder_id = folders.looks.folder.parent_id users.personal_folder_id = folders.looks.folder.parent_id users.home_folder_id = folders.parent_id users.personal_folder_id = folders.parent_id users.home_space_id = folders.dashboards.space.id users.personal_space_id = folders.dashboards.space.id users.home_space_id = folders.dashboards.space.parent_id users.personal_space_id = folders.dashboards.space.parent_id users.home_space_id = folders.looks.space.id users.personal_space_id = folders.looks.space.id users.home_space_id = folders.looks.space.parent_id users.personal_space_id = folders.looks.space.parent_id users.home_space_id = folders.looks.space_id users.personal_space_id = folders.looks.space_id users.id = folders.creator_id users.id = folders.dashboards.user_id users.id = folders.dashboards.folder.creator_id users.id = folders.dashboards.space.creator_id users.id = folders.looks.deleter_id users.id = folders.looks.last_updater_id users.id = folders.looks.user.id |
| lookml_dashboards |
users.home_folder_id = lookml_dashboards.folder.id users.personal_folder_id = lookml_dashboards.folder.id users.home_folder_id = lookml_dashboards.folder.parent_id users.personal_folder_id = lookml_dashboards.folder.parent_id users.home_space_id = lookml_dashboards.space.id users.personal_space_id = lookml_dashboards.space.id users.home_space_id = lookml_dashboards.space.parent_id users.personal_space_id = lookml_dashboards.space.parent_id users.id = lookml_dashboards.folder.creator_id users.id = lookml_dashboards.space.creator_id users.id = lookml_dashboards.user_id |
| looks |
users.home_folder_id = looks.folder.id users.personal_folder_id = looks.folder.id users.home_folder_id = looks.folder_id users.personal_folder_id = looks.folder_id users.home_folder_id = looks.folder.parent_id users.personal_folder_id = looks.folder.parent_id users.home_space_id = looks.space.id users.personal_space_id = looks.space.id users.home_space_id = looks.space.parent_id users.personal_space_id = looks.space.parent_id users.home_space_id = looks.space_id users.personal_space_id = looks.space_id users.id = looks.deleter_id users.id = looks.folder.creator_id users.id = looks.user.id users.id = looks.user_id |
| content_metadata_access |
users.group_ids = content_metadata_access.group_id |
| content_views |
users.group_ids = content_views.group_id users.id = content_views.user_id |
| groups |
users.group_ids = groups.id |
| groups_in_group |
users.group_ids = groups_in_group.id users.group_ids = groups_in_group.parent_group_id |
| user_attribute_group_values |
users.group_ids = user_attribute_group_values.group_id |
| versions |
users.looker_versions = versions.looker_release_version users.looker_versions = versions.current_version.full_version users.looker_versions = versions.supported_versions.full_version |
| role_groups |
users.role_ids = role_groups.role_id |
| roles |
users.role_ids = roles.id |
| content_metadata |
users.home_space_id = content_metadata.space_id users.personal_space_id = content_metadata.space_id |
| user_sessions |
users.sessions.id = user_sessions.id |
| connections |
users.id = connections.user_id |
| scheduled_plans |
users.id = scheduled_plans.user.id users.id = scheduled_plans.user_id |
| user_login_lockouts |
users.id = user_login_lockouts.user_id |
|
avatar_url STRING |
||||||||||||||
|
avatar_url_without_sizing STRING |
||||||||||||||
|
credentials_api3 ARRAY
|
||||||||||||||
|
credentials_email OBJECT
|
||||||||||||||
|
credentials_embed ARRAY
|
||||||||||||||
|
credentials_google OBJECT
|
||||||||||||||
|
credentials_ldap OBJECT
|
||||||||||||||
|
credentials_looker_openid OBJECT
|
||||||||||||||
|
credentials_oidc OBJECT
|
||||||||||||||
|
credentials_saml OBJECT
|
||||||||||||||
|
credentials_totp OBJECT
|
||||||||||||||
|
display_name STRING |
||||||||||||||
|
STRING |
||||||||||||||
|
embed_group_space_id STRING |
||||||||||||||
|
first_name STRING |
||||||||||||||
|
group_ids ARRAY |
||||||||||||||
|
home_folder_id STRING |
||||||||||||||
|
home_space_id STRING |
||||||||||||||
|
id
STRING |
||||||||||||||
|
is_disabled BOOLEAN |
||||||||||||||
|
last_name STRING |
||||||||||||||
|
locale STRING |
||||||||||||||
|
looker_versions ARRAY |
||||||||||||||
|
models_dir_validated BOOLEAN |
||||||||||||||
|
personal_folder_id STRING |
||||||||||||||
|
personal_space_id STRING |
||||||||||||||
|
presumed_looker_employee BOOLEAN |
||||||||||||||
|
role_ids ARRAY |
||||||||||||||
|
roles_externally_managed BOOLEAN |
||||||||||||||
|
sessions ARRAY
|
||||||||||||||
|
ui_state OBJECT |
||||||||||||||
|
url STRING |
||||||||||||||
|
verified_looker_employee BOOLEAN |
versions
The versions table contains info about the API versions supported by your Looker instance.
|
Full Table |
|
|
Primary Key |
looker_release_version |
| Useful links |
| Join versions with | on |
|---|---|
| users |
versions.looker_release_version = users.looker_versions versions.current_version.full_version = users.looker_versions versions.supported_versions.full_version = users.looker_versions |
|
current_version OBJECT
|
||||
|
looker_release_version
STRING |
||||
|
supported_versions ARRAY
|
workspaces
The workspaces table contains info about the workspaces available to the user who authorized the Looker integration in Stitch.
|
Full Table |
|
|
Primary Key |
id |
| Useful links |
| Join workspaces with | on |
|---|---|
| git_branches |
workspaces.projects.id = git_branches.project_id |
| project_files |
workspaces.projects.id = project_files.project_id |
| projects |
workspaces.projects.id = projects.id |
|
id
STRING |
||||||||||||||||
|
projects ARRAY
|
| Related | Troubleshooting |
Questions? Feedback?
Did this article help? If you have questions or feedback, feel free to submit a pull request with your suggestions, open an issue on GitHub, or reach out to us.