Drip feature snapshot
A high-level look at Stitch's Drip (v1) integration, including release status, useful links, and the features supported in Stitch.
| STITCH | |||
| Release status |
Released |
Supported by | |
| Stitch plan |
Standard |
API availability |
Not available |
| Singer GitHub repository |
Not applicable |
||
| REPLICATION SETTINGS | |||
| Anchor Scheduling |
Unsupported |
Advanced Scheduling |
Unsupported |
| Table-level reset |
Unsupported |
Configurable Replication Methods |
Unsupported |
| DATA SELECTION | |||
| Table selection |
Unsupported |
Column selection |
Unsupported |
| TRANSPARENCY | |||
| Extraction Logs |
Unsupported |
Loading Reports |
Unsupported |
Connecting Drip
Connecting Drip to Stitch is a three-step process:
Add Drip as a Stitch data source
- Sign into your Stitch account.
-
On the Stitch Dashboard page, click the Add Integration button.
-
Click the Drip icon.
-
Enter a name for the integration. This is the name that will display on the Stitch Dashboard for the integration; it’ll also be used to create the schema in your destination.
For example, the name “Stitch Drip” would create a schema called
stitch_dripin the destination. Note: Schema names cannot be changed after you save the integration. - Click Save Integration.
Generate a Drip Webhook URL
Once Stitch has successfully saved and created the Drip integration, you’ll be redirected to a page that displays your Drip webhook URL and token (which is blurred in the image below):
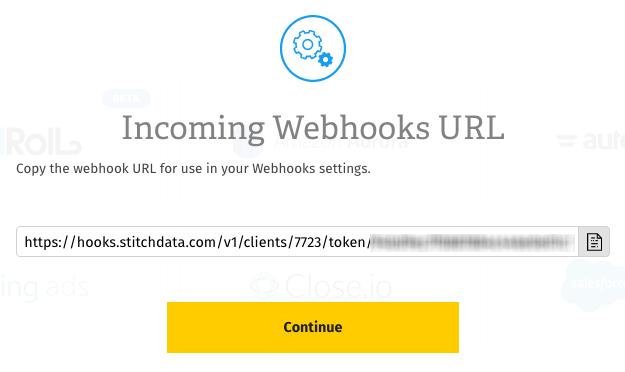
Click the Copy button to copy it.
Note that this particular URL won’t display in Stitch again once you click Continue. Think of this URL like you would your login or API credentials - keep it secret, keep it safe. You can, however, generate another URL should you need it.
Once you’ve copied your webhook URL, click Continue to wrap things up in Stitch.
Set up webhooks in Drip
The last step is to setup webhooks in your Drip account.
- Sign into your Drip account.
- Navigate to the Webhooks page.
- Paste the Stitch-generated webhook URL into the URL field.
- Click Create Webhook.
Replication
After you’ve successfully connected your Drip integration, Stitch will continuously replicate your webhook data into your destination.
- Webhooks and historical data
- How data is loaded into your destination
- How to query for the latest data
Webhooks and historical data
Because Drip data is sent to Stitch in real-time, this means that only new records are replicated to your destination. Most webhook-based integrations don’t retain historical data due to this as-it-happens approach.
In the event that our webhook service experiences downtime, you may notice some lag between an event occurring and the data appearing in your destination.
Loading behavior
This version of Stitch’s Drip integration loads data in an Append-Only fashion. When data is loaded using the Append-Only behavior, records are appended to the end of the table as new rows. Existing rows in the table aren’t updated even if the source has defined Primary Keys. Multiple versions of a row can exist in a table, creating a log of how a record has changed over time. Data stored this way can provide insights and historical details about how those rows have changed over time.
Refer to the Understanding loading behavior guide for more info and examples.
Query for the latest data
If you simply want the latest version of the object - or objects, if you elected to track more than one during the setup - in the integration’s table (data), you’ll have to adjust your querying strategy to account for the append-only method of replication. This is a little different than querying records that are updated using updated_at Incremental Replication.
To do this, you can use the _sdc_sequence column and the table’s Primary Key. The _sdc_sequence is a Unix epoch (down to the millisecond) attached to the record during replication and can help determine the order of all the versions of a row.
Note: If you didn’t define a Primary Key while setting up the integration, the Primary Key for the table will be __sdc_primary_key.
If you wanted to create a snapshot of the latest version of this table, you could run a query like this:
SELECT * FROM [stitch-redshift:stitch-drip.data] o
INNER JOIN (
SELECT
MAX(_sdc_sequence) AS seq,
[primary-key]
FROM [stitch-redshift:stitch-drip.data]
GROUP BY [primary-key]) oo
ON o.[primary-key] = oo.[primary-key]
AND o._sdc_sequence = oo.seq
This approach uses a subquery to get a single list of every row’s Primary Key and maximum sequence number. It then joins the original table to both the Primary Key and maximum sequence, which makes all other column values available for querying.
Schema
In v1 of the Stitch Incoming Webhooks integration, Stitch will create a single table - called data - in the webhook integration schema (this will be the name you enter in the Integration Schema field when you set up Drip) of your data warehouse.
The schema of this table will contain two “types” of columns:
- Columns used by Stitch (prepended with
_sdc), and - Columns sent by the provider’s webhook API
Aside from the Stitch columns, the schema of this table will depend entirely on Drip’s webhook API. With the exception of the _sdc fields, Stitch does not augment Incoming Webhooks data nor does it have any control over the fields sent by the webhook provider.
Webhook URLs & Security
Stitch allows you to generate up to 2 Drip webhook URLs at a time. These URLs contain security access tokens and as such, have access to your Drip account.
If you ever need to change your webhook URL, you can do so in the Integration Settings page after the integration has been created:
- Click into the integration from the Stitch Dashboard page.
- Click the Settings button.
- In the Webhook URLs section, click the Generate Webhook URL button.
- A new webhook URL will display. Press the clipboard icon to copy it.
- Follow the steps in the Setting Up Webhooks in Drip section to update the webhook URL in Drip.
- After you’ve updated the webhook URL in Drip, click the Revoke button next to the oldest webhook URL in Stitch. This will invalidate the token and revoke access.
| Related | Troubleshooting |
Questions? Feedback?
Did this article help? If you have questions or feedback, feel free to submit a pull request with your suggestions, open an issue on GitHub, or reach out to us.