Skip Navigation
Big data and cloud data warehouses are helping modern organizations leverage business intelligence (BI) and analytics for decision-making and new insights. Maintaining a data warehouse requires building a data ingestion process, and that in turn requires an understanding of ETL, its use cases, and its relationship with other components in the data analytics stack.
What is ETL?
ETL (extract, transform, load) is a general process for replicating data from source systems to target systems. It encompasses aspects of obtaining, processing, and transporting information so an enterprise can use it in applications, reporting, or analytics. Let's take a more detailed look at each step.
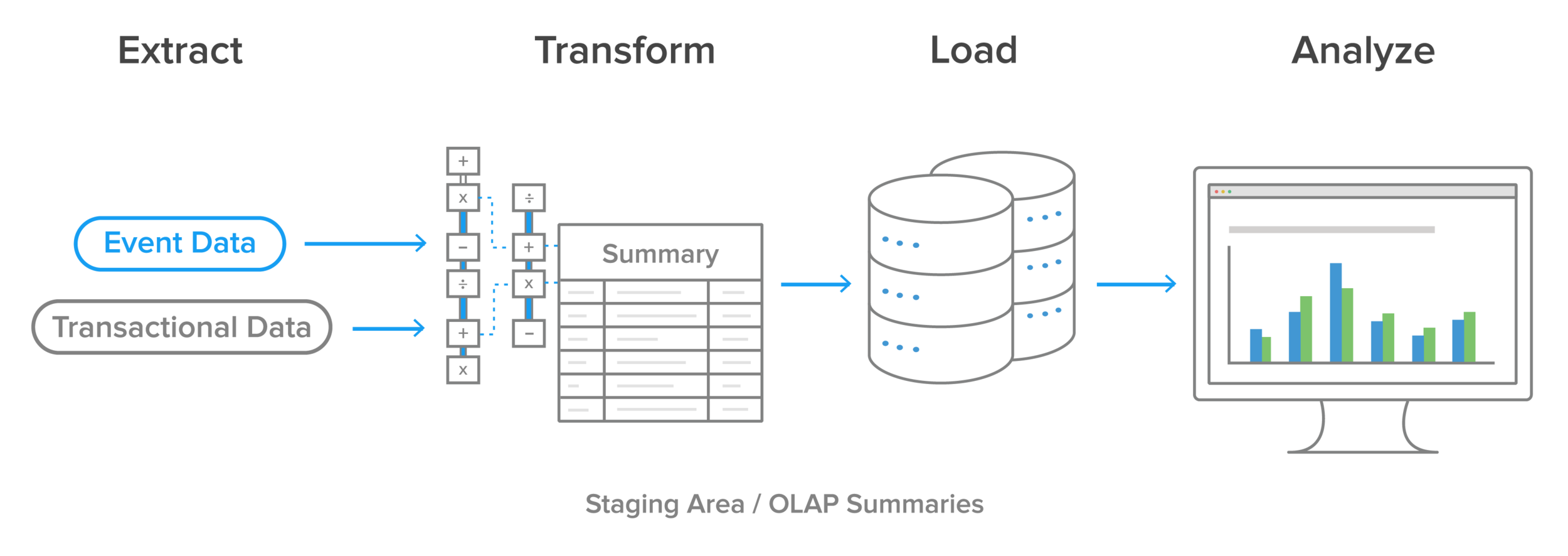
Extract
Extraction involves accessing source systems and reading and copying the data they contain. A data engineer may extract source data to a temporary location such as a data lake or a staging table in a database in anticipation of the steps that follow.
The extraction step focuses on collecting data. Many enterprise data sources are transactional systems where the data is stored in relational databases that are designed for high throughput and frequent write and update operations. These online transaction processing (OLTP) systems are optimized for operational data defined by schemas and divided into tables, rows, and columns. The transactional systems may run on local servers or on SaaS platforms. Other potential sources include flat files such as HTML or log files.
Transform
Transformation alters the structure, format, or values of the extracted data through different data transformation operations. Business requirements and the characteristics of the destination system determine what transformations are necessary.
Transformations fall into three general categories: validating, cleansing, and preparing data for analysis. Some of the most important transformations are mapping data types from source to target systems, flattening semistructured data intended for a relational database, and data validation.
Most organizations now access and use diverse data sources, from operational, financial, and sales databases to application APIs and scraped web data. This data may be unstructured and therefore unsuitable for use in data analytics processes. The transformation step of the ETL process can ensure that data enters the data warehouse in a required format and structure, allowing data analysts to work with it more easily.
For example, an ETL process can extract web data such as JSON records, HTML pages, or XML responses, parse valuable information or simply flatten these formats, then feed the resulting data into a data warehouse.
Load
The loading stage involves writing data into a target, which may be a data warehouse, data lake, or analytics application or platform that accepts direct data feeds.
Data can exist in multiple final states and locations within a destination. For example, in a data warehouse, the same records might exist as part of a snapshot table including a week of data and in a larger archival table containing all loaded historical records.
At this stage the data is available for online analytical processing (OLAP) systems, which are optimized for queries rather than transactions. OLAP systems may also serve as data repositories for manual machine learning or predictive analyses.
ETL data from 100+ sources to your data warehouse
Why use ETL?
Data warehousing and ETL make up two layers of the data analytics stack. Enterprises use data warehouses to store and access cleansed, consistent, and high-quality business data, sourced from diverse origin systems. ETL is the set of methods and tools used to populate and update these warehouses.
Once an ETL process has replicated data to the data warehouse, analytics and business intelligence teams — data analysts, data engineers, data scientists — and SQL-savvy business users can all work with it.
ETL's place in the data landscape
ETL is connected to many other important data concepts and practices, including big data, business intelligence, machine learning, metadata, data quality, and self-service analytics.
Big data
Big data describes the availability, diversity, and volume of data that modern enterprises handle. Thanks to faster and more efficient ingestion, organizations can make big data available to the people and systems that transform raw information into business insights.
Business intelligence
BI is an umbrella term that includes infrastructure, tools, and software systems, all of which rely on the data ETL replicates. Ingested data arrives in central repositories and business applications, where BI tools can access it to produce insights and support decision-making processes. The dashboards, reports, and summaries BI tools create would not exist without ETL.
Data quality and data governance
ETL processes generate detailed logging, which helps with data auditing, troubleshooting errors and incorrect values, and generally ensuring high-quality data. Most ETL tools also include a wide array of data quality features, which can validate or cleanse data.
ETL can also facilitate data governance processes. Arranging the reading, processing, and writing of data into distinct stages allows troubleshooters to pinpoint exactly when and where potential problems have occured.
Machine learning
ETL also feeds sophisticated analytical processes such as machine learning. Machine learning consists of the complex algorithms and models that allow computer systems to analyze data intelligently. From prescriptive analytics to advanced statistical models, machine learning methods all rely on the clean and readily available data ETL provides.
Metadata, continuity, and historical context
ETL can be a powerful tool for facilitating data tracking throughout its lifecycle, at every processing and transformation step. Data warehouses maintain metadata for objects, ranging from individual rows and columns in database tables to characteristics of the entire data warehouse, and organizations can use this metadata to track data as it changes. Knowing where data originated and how it has been modified can help organizations evaluate its impact on computing and storage resources and discover parts of the data pipeline that can be improved.
ETL also allows organizations to keep older, archival records accessible and centralized. This provides stakeholders with more historical context for decision-making. It also makes it easier to back up critical data and maintain a history of database systems and data warehouses.
Self-service analytics for the uninitiated
ETL is a vital component in self-service analytics processes that give more stakeholders the opportunity to work directly with data. ETL codifies repeated, automatable processes and outputs cleansed and well-structured data, allowing nontechnical stakeholders to access greater amounts of high-quality information. For example, it's easier for such stakeholders to use pre-existing reporting tables and views in a data warehouse.
ETL and ELT
ETL is part of the ongoing evolution of data integration. It began in the 1970s, as organizations expanded the scale and scope of their IT systems and had to integrate data from disparate sources into centralized repositories. These early repositories evolved into server-based data warehouses, where enterprise data was consolidated and accessible. On-premises analytics systems had fixed amounts of CPU and storage resources, and were optimized for data retrieval and reporting. In that environment, it made sense to do as the prep work (transformation) prior to loading data into the warehouse in order to avoid consuming cycles that the analysts needed.
Today, in the age of big data, server-based storage and processing is giving way to the cloud. For cloud-based data warehouses, ELT (extract, load, transform), is a better choice, because the cloud platform provides scalable computing resources, which removes the need to process data in staging areas before it's loaded onto the data warehouse.
Learn more about the next generation of ETL
ETL tools: Build a pipeline to your data warehouse with Stitch
Stitch is a simple data pipeline that makes it easy to transport data between data sources and your data warehouse of choice. Try a free trial of Stitch to start replicating data to your data warehouse today.
Give Stitch a try, on us
Stitch streams all of your data directly to your analytics warehouse.
Set up in minutesUnlimited data volume during trial