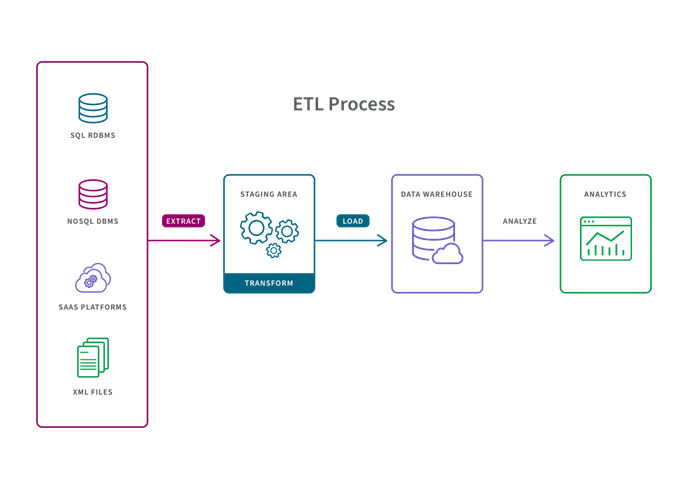
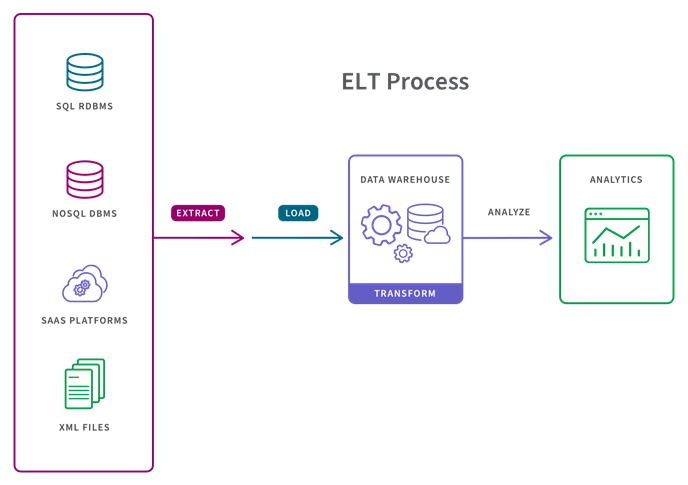
Data Transformation Process
The process of data transformation involves several key steps, which may vary based on your specific context and requirements. Plus, these workflows can be handled manually, automated or a combination of both. Here are the most common steps:

Data Discovery and Interpretation
Understand the types of data you currently have from different sources and determine what format it needs to be transformed into.
Consider file extensions, but also look deeper into the actual data structure to avoid assumptions.
Identify the target format for the transformed data.
Pre-Translation Data Quality Check
Before proceeding, verify the quality of your source data.
Detect missing or corrupt values that could cause issues during subsequent transformation steps.
Data Mapping and Code Development
Map the source data fields to their corresponding fields in the target format.
Use tools or develop scripts to perform the necessary transformations.
Code Execution and Validation
Execute the transformation code or processes (e.g., aggregations, calculations, filtering) to align the data with the desired format.
Validate the transformed data and data model to ensure correctness and consistency.
Address any discrepancies or errors that arise during this step.
Data Review and Documentation
Review the transformed data to confirm its accuracy and completeness.
Document the transformation process, including details about applied rules, mappings, and any adjustments made.
Maintain clear records for future reference and troubleshooting.
Keep in mind that not all your data will require transformation, on rare occasions, your source data can be used as is.