Skip Navigation
Builders erect houses from blueprints, with architecture constrained by physical limitations. When someone moves in, they decide how the inside of their home should look, and their preferences determine interior decor and design. Data warehouses are similar: their architecture is standardized, but their design is adapted to business and user needs.
Data warehouse architecture is inherent to the main hosting platform or service selected by an organization. It's a built-in, static infrastructure, and hosts all the specific tools and processes that eventually make up the warehouse.
Data warehouse design, however, should be customized with an understanding of an organization's stakeholders and strategic requirements. Short-sighted design choices limit the potential and performance of enterprise data warehouses.
What is a data warehouse architecture?
Before discussing data warehouse design, it's important to understand the foundational role that architecture plays in both on-premises and cloud data warehouses.
Data warehouses contain historical, current, and critical enterprise data. They form the storage and processing platform underlying reporting, dashboards, business intelligence, and analytics.
Traditional data warehouse architecture
Originally, data warehouses ran on on-premises hardware, and were architected in three distinct tiers:
- The bottom tier of traditional data warehouse architecture is the core relational database system, and contains all data ingestion logic and ETL processes. The ETL processes connect to data sources and extract data to local staging databases, where it's transformed then forwarded to production servers.
- In the middle tier, an online analytical processing (OLAP) server powers reporting and analytic logic. At this tier data architects may further transform the data, aggregate it, or enrich it before running business intelligence processes.
- The top tier is the front end, the user-facing layer. It contains web interfaces for stakeholders to access and query reports or analytical results, as well as visualization and business intelligence tools for end users running ad-hoc analysis.
Try Stitch for free for 14 days
Drawbacks of traditional architecture
A major issue associated with on-premises data warehouses is the cost of deployment and management. Businesses must purchase server hardware, set aside space to house it, and devote IT staff to set it up and administer it.
More important, however, is the fact that on-premises hardware is more difficult to scale than cloud-based storage and computing. Managers and decision-makers must get approval for new hardware, assign budgets, and wait for shipment, and then engineers and IT specialists must installation and set up both hardware and software. After installation, operational systems may not be used to capacity, which means money wasted on resources that aren't contributing value.
This type of mission-critical infrastructure requires a high level of expenditure, attention, and employee specialization when deployed on-premises. Modern cloud services don't have these problems, because resources are scalable and pricing is too.
The modern cloud data warehouse
Cloud data warehouses are more adaptable, performant, and powerful than in-house systems. Businesses can save on staffing and can put their IT staff to better use, because their infrastructure is managed by dedicated specialists.
Cloud data warehouses feature column-oriented databases, where the unit of storage is a single attribute, with values from all records. Columnar storage does not change how customers organize or represent data, but allows for faster access and processing.
Cloud data warehouses also offer automatic, near-real-time scalability and greater system reliability and uptime than on-premises hardware, and transparent billing, which allows enterprises to pay only for what they use.
Because cloud data warehouses don't rely on the rigid structures and data modeling concepts inherent in traditional systems, they have diverse architectures.
- Amazon Redshift's approach is akin to infrastructure-as-a-service (IaaS) or platform-as-a-service (PaaS). Redshift is highly scalable, provisioning clusters of nodes to customers as their storage and computing needs evolve. Each node has individual CPU, RAM, and storage space, facilitating the massive parallel processing (MPP) needed for any big data application, especially the data warehouse. Customers have to be responsible for some capacity planning and must provision compute and storage nodes on the platform.
- The Google BigQuery approach is more like software-as-a-service (SaaS) that allows interactive analysis of big data. It can be used alongside Google Cloud Storage and technologies such as MapReduce. BigQuery differentiates itself with a serverless architecture, which means users cannot see details of resource allocation, as computational and storage provisioning happens continuously and dynamically.
- Snowflake's automatically managed storage layer can contain structured or semistructured data, such as nested JSON objects. The compute layer is composed of clusters, each of which can access all data but work independently and concurrently to enable automatic scaling, distribution, and rebalancing. Snowflake is a data warehouse-as-a-service, and operates across multiple clouds, including AWS, Microsoft Azure and, soon, Google Cloud.
- Microsoft Azure SQL Data Warehouse is an elastic, large-scale data warehouse PaaS that leverages the broad ecosystem of SQL Server. Like other cloud storage and computing platforms, it uses a distributed, MPP architecture and columnar data store. It gathers data from databases and SaaS platforms into one powerful, fully-managed centralized repository.
Data warehousing schemas
Data warehouses are relational databases, and they are associated with traditional schemas, which are the ways in which records are described and organized.
- A snowflake schema arranges tables and their connections so that a representative entity relationship diagram (ERD) resembles a snowflake. A centralized fact table connects to many dimension tables, which themselves connect to more dimension tables, and so on. Data is normalized.
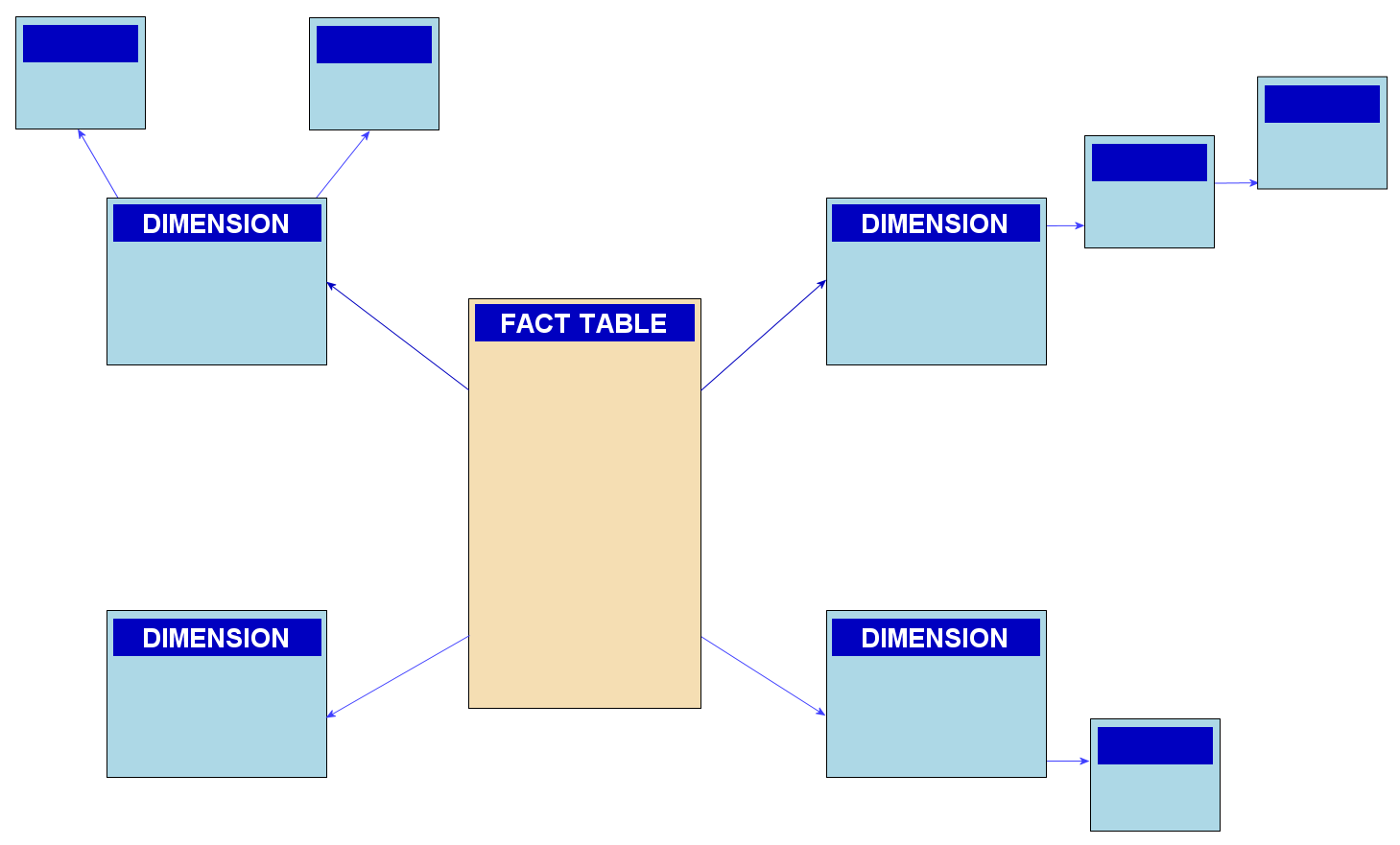
Snowflake schema: SqlPac
{kind=link}
- The simpler star schema is a special case of the snowflake schema. Only one level of dimension tables is connected to the central fact table, resulting in ERDs with star shapes. These dimension tables are denormalized, containing all attributes and information associated with the particular type of record they hold.
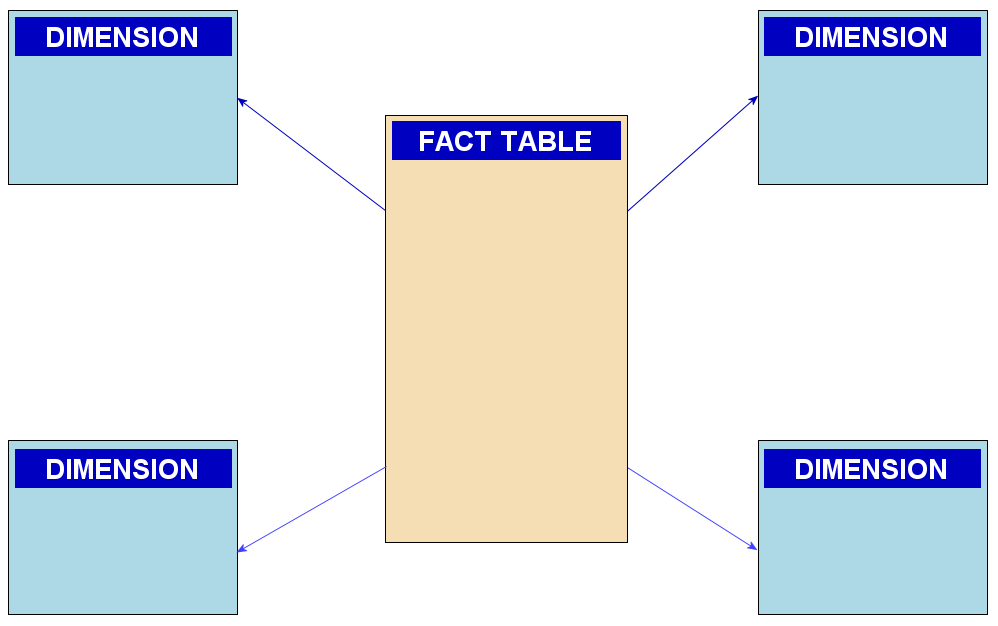
Star schema: SqlPac
{kind=link}
Learn more about the next generation of ETL
Anticipating major design flaws
A complex system like a modern data warehouse includes many dependencies. Errors may propagate throughout the system and make mistakes difficult to rectify.
- Organizations should strive to be future-proof. Design choices based exclusively on immediate needs may cause problems later.
- Data warehouse design is a collaborative process that should include all key stakeholders. Leaving out end users during planning means less engagement. The same applies when leaving design entirely up to the IT department. High-level managers and decision-makers should provide the overall business strategy.
- Data quality should be a priority. Strong data governance practices ensure clean data and encourage adherence to rules and regulations.
- Subject matter experts should lead the data modeling process. This guidance ensures that the data pipeline will be robust, consistently organized, and documented.
- Businesses should design for optimized query performance, pulling only relevant data, using efficient data structures, and tuning systems often. OLAP cube design in particular is critical: It allows super-fast and intuitive analysis of data according to the multiple dimensions of a business problem.
Try Stitch with your cloud data warehouse today
7 steps to robust data warehouse design
After selecting a data warehouse, an organization can focus on specific design considerations. Here are seven steps that help ensure a robust data warehouse design:
1. User needs: A good data warehouse design should be based on business and user needs. Therefore, the first step in the design procedure is to gather requirements, to ensure that the data warehouse will be integrated with existing business processes and be compatible with long-term strategy. Enterprises must determine the purpose of their data warehouse, any technical requirements, which stakeholders will benefit from the system, and which questions will be answered with improved reporting, business intelligence (BI), and analytics.
2. Physical environment: Enterprises that opt for on-premises architecture must set up the physical environment, including all the servers necessary to power ETL processes, storage, and analytic operations. Enterprises can skip this step if they choose a cloud data warehouse.
3. Data modeling: Next comes data modeling, which is perhaps the most important planning step. The data modeling process should result in detailed, reusable documentation of a data warehouse's implementation. Modelers assess the structure of data in sources, decide how to represent these sources in the data warehouse, and specify OLAP requirements, including level of processing granularity, important aggregations and measures, and high-level dimensions or context.
4. ETL/ELT: The next step is the selection of an ETL/ELT solution. ETL transforms data prior to the loading stage. When businesses used costly in-house analytics systems, it made sense to do as much prep work as possible, including transformations, prior to loading data into the warehouse. However, ELT is a better approach when the destination is a cloud data warehouse. Organizations can transform their raw data at any time, when and as necessary for their use case, and not as a step in the data pipeline.
5. Semantic layer: Next up is designing the data warehouse's semantic layer. Based on previously documented data models, the OLAP server is implemented to support the analytical queries of individual users and to empower BI systems. This step determines the core analytical processing capabilities of the data warehouse, so data engineers should carefully consider time-to-analysis and latency requirements.
6. Reporting layer: With analytic infrastructure built and implemented, an organization can design a reporting layer. An administrator designates groups and end users, describes and enforces permissible access, and implements reporting interfaces or delivery methods.
7. Test and tune: All that remains is to test and tune the completed data warehouse and data pipeline. Businesses should assess data ingestion and ETL/ELT systems, tweak query engine configurations for performance, and validate final reports. This is a continuous process requiring dedicated testing environments and ongoing engagement.
Stitch gets your data to cloud data warehouses quickly
If you choose to work with a cloud data warehouse, you need a way to populate it with the data in your existing databases and SaaS tools. That's where Stitch comes in.
Stitch is a cloud-based ETL tool that pulls your data from more than 100 different sources to key data destinations like Redshift, BigQuery, Snowflake, and Azure SQL Data Warehouse. Set up a free trial now and get data into your warehouse quickly.
Give Stitch a try, on us
Stitch streams all of your data directly to your analytics warehouse.
Set up in minutesUnlimited data volume during trial