Google BigQuery is a fully managed, fast, low cost analytics data warehouse. BigQuery is pay-as-you-go, making it cost-effective for all volumes of data. Its serverless architecture makes powerful analytical and business intelligence queries available via SQL to companies of all types.
For more information, check out Google’s Google BigQuery overview.
This guide serves as a reference for version 2 of Stitch’s Google BigQuery destination.
Details and features
Stitch features
High-level details about Stitch’s implementation of Google BigQuery, such as supported connection methods, availability on Stitch plans, etc.
| Release status |
Released |
| Stitch plan availability |
All Stitch plans |
| Stitch supported regions |
Operating regions determine the location of the resources Stitch uses to process your data. Learn more. |
| Supported versions |
Not applicable |
| Connect API availability |
Supported
This version of the Google BigQuery destination can be created and managed using Stitch’s Connect API. Learn more. |
| SSH connections |
Unsupported
Stitch does not support using SSH tunnels to connect to Google BigQuery destinations. |
| SSL connections |
Supported
Stitch will attempt to use SSL to connect by default. No additional configuration is needed. |
| VPN connections |
Unsupported
Virtual Private Network (VPN) connections may be implemented as part of a Premium plan. Contact Stitch Sales for more info. |
| Static IP addresses |
Supported
This version of the Google BigQuery destination has static IP addresses that can be whitelisted. |
| Default loading behavior |
Selected by you |
| Nested structure support |
Supported
|
Destination details
Details about the destination, including object names, table and column limits, reserved keywords, etc.
Note: Exceeding the limits noted below will result in loading errors or rejected data.
| Maximum record size |
20MB |
| Table name length |
1,024 characters |
| Column name length |
128 characters |
| Maximum columns per table |
10,000 |
| Maximum table size |
None |
| Maximum tables per database |
None |
| Case sensitivity |
Insensitive |
| Reserved keywords |
Refer to the Reserved keywords documentation. |
Supported Google Cloud Storage regions
When you set up a Google BigQuery destination, you’ll select a Google Storage location. This determines the location of the internal Google Storage bucket Stitch uses during the replication process.
Stitch supports the following Google Cloud Storage regions for version 2 of the Google BigQuery destination:
| Region description | Region name | |
| Americas | Los Angeles |
us-west2
|
| Montréal |
northamerica-northeast1
|
|
| Northern Virginia |
us-east4
|
|
| São Paulo |
southamerica-east1
|
|
| United States |
US
|
|
| Europe | European Union |
EU
|
| Finland |
europe-north1
|
|
| Frankfurt |
europe-west3
|
|
| London |
europe-west2
|
|
| Zürich |
europe-west6
|
|
| Asia Pacific | Hong Kong |
asia-east2
|
| Mumbai |
asia-south1
|
|
| Osaka |
asia-northeast2
|
|
| Singapore |
asia-southeast1
|
|
| Sydney |
australia-southeast1
|
|
| Taiwan |
asia-east1
|
|
| Tokyo |
asia-northeast1
|
Google BigQuery pricing
Unlike many other cloud-based data warehouse solutions, Google BigQuery’s pricing model is based on usage and not a fixed-rate. This means that your bill can vary over time.
Before fully committing yourself to using Google BigQuery as your data warehouse, we recommend familiarizing yourself with the Google BigQuery pricing model and how using Stitch may impact your costs.
Learn more about Stitch & Google BigQuery pricing
Replication
Replication process overview
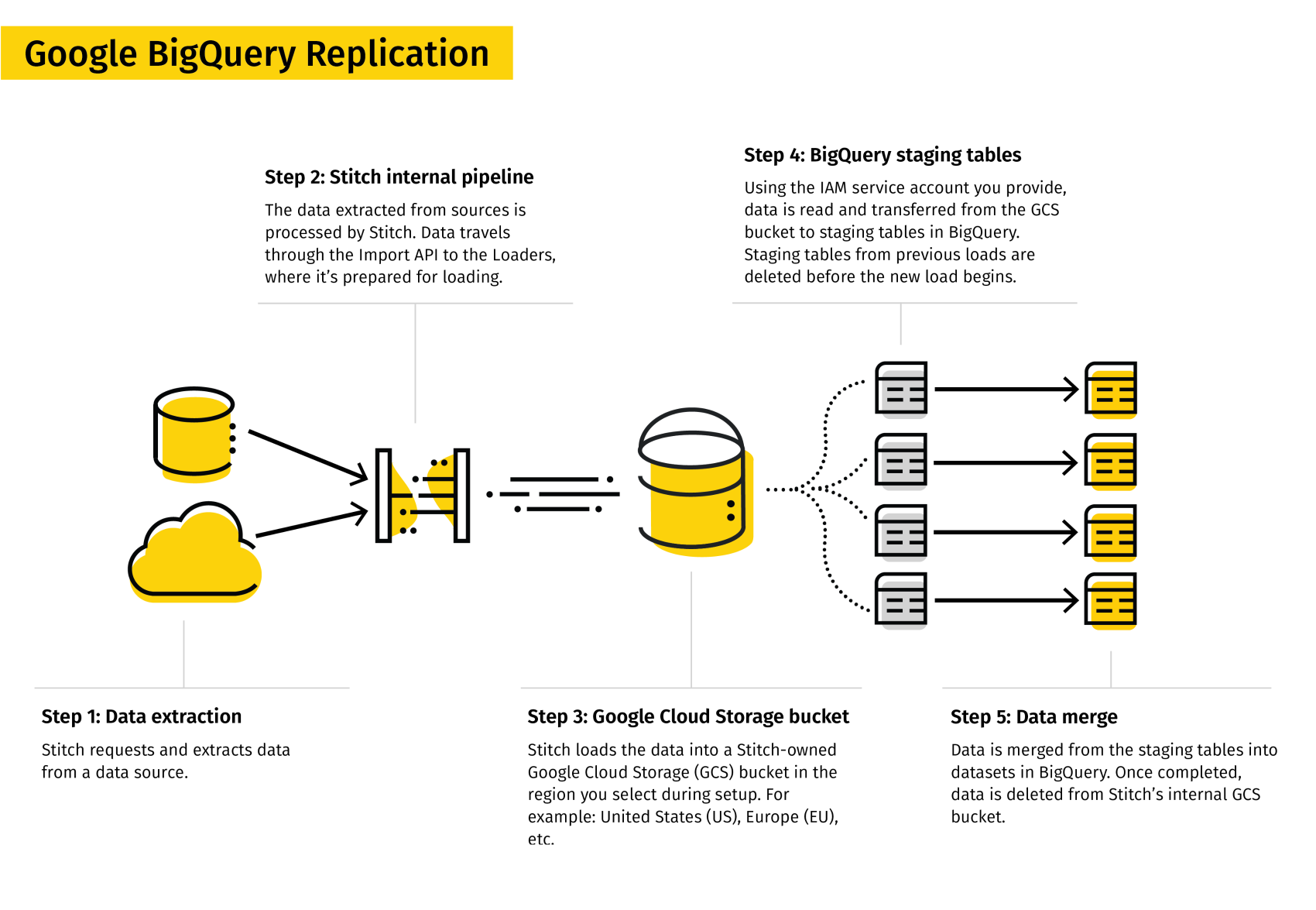
Step 1: Data extraction
Stitch requests and extracts data from a data source. Refer to the System overview guide for a more detailed explanation of the Extraction phase.
Step 2: Stitch's internal pipeline
The data extracted from sources is processed by Stitch. Stitch’s internal pipeline includes the Prepare and Load phases of the replication process:
- Prepare: During this phase, the extracted data is buffered in Stitch’s durable, highly available internal data pipeline and readied for loading.
- Load: During this phase, the prepared data is transformed to be compatible with the destination, and then loaded. Refer to the Transformations section for more info about the transformations Stitch performs for Google BigQuery destinations.
Refer to the System overview guide for a more detailed explanation of these phases.
Step 3: Google Cloud Storage bucket
Stitch loads the data into a Stitch-owned Google Cloud Storage (GCS) bucket in the region you select during destination setup.
Step 4: BigQuery staging tables
Using the IAM service account you provide during destination setup, data is read and transferred from the GCS bucket to staging tables in Google BigQuery. Staging tables from previous loads are deleted before the new load begins.
Step 5: Data merge
Data is merged from the staging tables into datasets in Google BigQuery.
The loading behavior you select during setup determines not only what the data looks like in the destination, but the method Stitch uses to load it. Note: The loading behavior can also affect your Google BigQuery costs.
Once completed, the data is deleted from Stitch’s internal GCS bucket.
Loading behavior
How data is loaded into Google BigQuery depends on the Loading behavior setting you define during destination setup:
-
Upsert: Existing rows are updated in tables with defined Primary Keys. A single version of a row will exist in the table.
-
Append-Only: Existing rows aren’t updated. Multiple versions of a row can exist in a table, creating a log of how a row changed over time.
Because of this loading strategy, querying may require a different strategy than usual. Using some of the system columns Stitch inserts into tables will enable you to locate the latest version of a record at query time.
Refer to the Understanding loading behavior guide for more info.
Note: Loading behavior can impact your Google BigQuery costs.
Primary Keys
Stitch requires Primary Keys to de-dupe incrementally replicated data. To ensure Primary Key data is available, Stitch creates an _sdc_primary_keystable in every integration dataset. This table contains a list of all tables in an integration’s dataset and the columns those tables use as Primary Keys.
Refer to the _sdc_primary_keys table documentation for more info.
Note: Removing or altering this table can lead to replication issues.
Incompatible sources
No compatibility issues have been discovered between Google BigQuery and Stitch's integration offerings.
See all destination and integration incompatibilities.
Transformations
System tables and columns
Stitch will create the following tables in each integration’s dataset:
Additionally, Stitch will insert system columns (prepended with _sdc) into each table.
Data typing
Stitch converts data types only where needed to ensure the data is accepted by Google BigQuery. In the table below are the data types Stitch supports for Google BigQuery destinations, and the Stitch types they map to.
- Stitch type: The Stitch data type the source type was mapped to. During the Extraction and Preparing phases, Stitch identifies the data type in the source and then maps it to a common Stitch data type.
- Destination type: The destination-compatible data type the Stitch type maps to. This is the data type Stitch will use to store data in Google BigQuery.
- Notes: Details about the data type and/or its allowed values in the destination, if available. If a range is available, values that exceed the noted range will be rejected by Google BigQuery.
| Stitch type | Destination type | Notes |
| ARRAY | ARRAY | |
| BIGINT | INTEGER |
|
| BOOLEAN | BOOLEAN | |
| DATE | TIMESTAMP |
|
| DOUBLE | FLOAT | |
| FLOAT | FLOAT | |
| INTEGER | INTEGER |
|
| NUMBER | NUMERIC |
|
| RECORD | RECORD | |
| STRING | STRING |
|
JSON structures
Google BigQuery supports nested records within tables, whether it’s a single record or repeated values. Refer to the Google BigQuery and Storing Nested Data Structures documentation for more info and examples.
Column names
Column names in Google BigQuery:
- Must contain only letters (a-z, A-Z), numbers (0-9), or underscores (
_) - Must begin with a letter or an underscore
-
Must be less than the maximum length of 128 characters. Columns that exceed this limit will be rejected by Google BigQuery.
- Must not be prefixed or suffixed with any of Google BigQuery’s or Stitch’s reserved keyword prefixes or suffixes
Stitch will perform the following transformations to ensure column names adhere to the rules imposed by Google BigQuery:
| Transformation | Source column | Destination column |
| Convert uppercase and mixed case to lowercase |
CUSTOMERID or cUsTomErId
|
customerid
|
| Convert spaces to underscores |
customer id
|
customer_id
|
| Convert special characters to underscores |
customer#id or !customerid
|
customer_id and _customerid
|
| Convert leading numbers to underscores |
4customerid
|
_customerid
|
Timezones
Google BigQuery will store the value in UTC as TIMESTAMP.
More info about timestamp data types can be found in BigQuery’s documentation.
Compare destinations
Not sure if Google BigQuery is the data warehouse for you? Check out the Choosing a Stitch Destination guide to compare each of Stitch’s destination offerings.
| Related | Troubleshooting |
Questions? Feedback?
Did this article help? If you have questions or feedback, feel free to submit a pull request with your suggestions, open an issue on GitHub, or reach out to us.