Data.world helps you host and share your data, collaborate with your team, and capture context and conclusions as you work.
This guide serves as a reference for version 1 of Stitch’s data.world destination.
Details and features
Stitch features
High-level details about Stitch’s implementation of data.world, such as supported connection methods, availability on Stitch plans, etc.
| Release status |
Released |
| Stitch plan availability |
All Stitch plans |
| Stitch supported regions |
Operating regions determine the location of the resources Stitch uses to process your data. Learn more. |
| Supported versions |
Not applicable |
| Connect API availability |
Unsupported
This version of the data.world destination is not currently available in Stitch’s Connect API. |
| SSH connections |
Unsupported
Stitch does not support using SSH tunnels to connect to data.world destinations. |
| SSL connections |
Supported
Stitch will attempt to use SSL to connect by default. No additional configuration is needed. |
| VPN connections |
Not applicable |
| Static IP addresses |
Supported
This version of the data.world destination has static IP addresses that can be whitelisted. |
| Default loading behavior |
Upsert |
| Nested structure support |
Supported
|
Destination details
Details about the destination, including object names, table and column limits, reserved keywords, etc.
Note: Exceeding the limits noted below will result in loading errors or rejected data.
data.world pricing
While Stitch is compatible with all of data.world plans, keep in mind that the number of private projects/datasets and the size maximum of those projects varies by plan.
For more information on data.world’s plans, refer to their pricing page.
Replication
Replication process overview
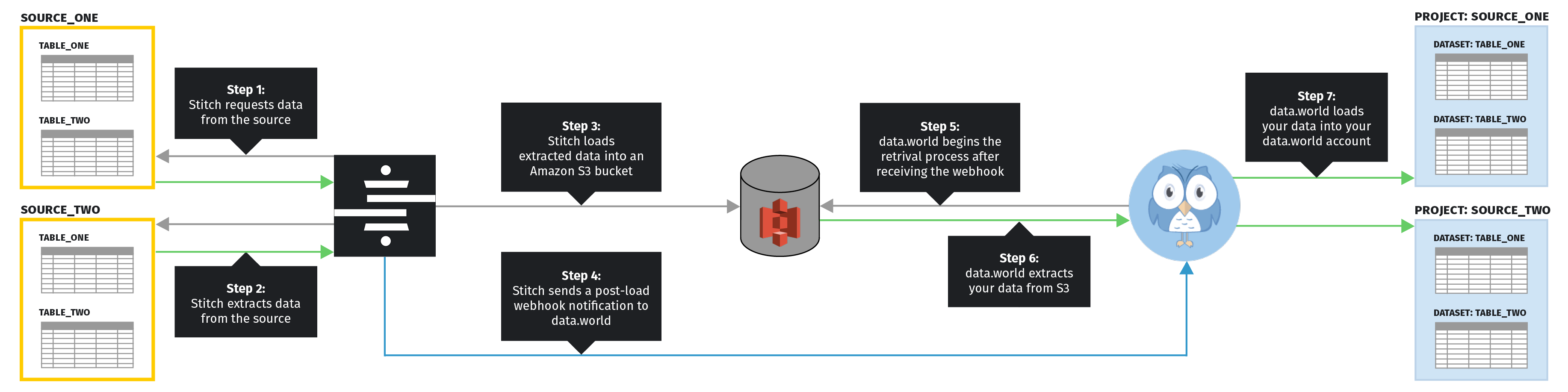
Click to enlarge
Steps 1 & 2: Data extraction
Stitch requests and extracts data from a data source. Refer to the System overview guide for a more detailed explanation of the Extraction phase.
Step 3: Load data into shared S3 bucket
Stitch will loads the raw JSON data into an Amazon S3 bucket shared between Stitch and data.world.
Step 4: Notify data.world
After Stitch successfully finishes loading into Amazon S3, a webhook notification is sent to data.world to trigger the retrieval process.
Steps 5 & 6: data.world retrieves data from S3
Data.world retrieves the data destined for your account from the shared Amazon S3 bucket.
Step 7: data.world loads your data
Data.world loads the data into your data.world account. Refer to the Loading behavior section below for more info on how your data will be structured in data.world.
Loading behavior
When data.world retrieves an integration’s data from the Amazon S3 bucket, it will be loaded into your data.world account as a project with child datasets.
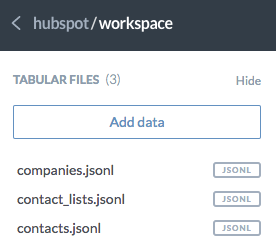
For each integration you connect to Stitch, a project with the same name will be created in data.world. The tables you set to replicate will be stored as JSON datasets within the project.
For example: If you named an integration HubSpot in Stitch and selected the companies, contact_lists, and contacts tables to replicate, your workspace in your data.world account would be the same as the image on the right.
The dataset schema will contain the attributes you set to replicate in Stitch along with a few _sdc columns.
Incompatible sources
No compatibility issues have been discovered between data.world and Stitch's integration offerings.
See all destination and integration incompatibilities.
Transformations
System columns
The dataset schema will contain the attributes you set to replicate in Stitch along with a few _sdc columns. These are system columns generated by Stitch for replicating data.
For information about the data available in SaaS integrations - including column descriptions and potential data values - refer to the Schema section of any of our integrations docs.
JSON structures
All replicated data is stored as JSON, both in Amazon S3 and in data.world after the final load is complete. This means that nested structures are stored intact.
| Related | Troubleshooting |
Questions? Feedback?
Did this article help? If you have questions or feedback, feel free to submit a pull request with your suggestions, open an issue on GitHub, or reach out to us.